以下内容由AI辅助生成
引言:三个核心抽象
在理解 Transformer 之前,可以先记住三句话:
- Attention = 状态之间的信息路由
- FFN = 状态内部的非线性变换
- Multi-Head = 多种关系子空间的并行建模
这三句话不是对 Transformer 的技巧性总结,而是对其核心思想的抽象表达。它们并非 Transformer 独有的新概念,而是长期存在于神经网络中的通用思想,在 Transformer 中被系统化、模块化、工程化地组织在了一起。
Transformer 的重要性不在于它「发明了什么全新的思想」,而在于它第一次把信息如何流动和状态如何更新这两件事彻底解耦,并用统一、可扩展的结构反复堆叠,从而构建出今天的大模型体系。
整体架构概览
![]()
1 | 输入序列: [x₁, x₂, ..., xₙ] |
上图展示了 Transformer 的整体数据流:输入经过 embedding 和位置编码后,通过 N 层相同的 Block 进行处理。每个 Block 包含两个核心组件(Attention 和 FFN),以及用于稳定训练的残差连接和归一化。下文将逐一展开这些组件的细节。
一、Transformer 解决什么问题?
Transformer 是一种序列建模架构。它的输入和输出本质上都是 token 序列,目标是学习如下形式的函数:
其中最大的困难只有一个:
每个位置的表示,既要知道其他位置的信息,又要知道自己该如何变化。
Transformer 对这个问题的解决方案:
- 用 Attention 解决「谁和谁交互」
- 用 FFN 解决「交互之后如何变化」
这构成了 Transformer 的第一性原理。
更进一步看,Transformer 用纯 Attention 结构解决了序列建模的并行性和长距离依赖问题,也是现代大模型的结构源头:
- 并行性主要由 Self-Attention 机制 解决
- 长距离依赖主要由 Self-Attention + 多头机制 + 结构设计 共同解决
并行性是怎么解决的?
核心在于 Self-Attention + 去掉 RNN/CNN:
- Self-Attention 对整个序列做矩阵运算
- 所有 token 同时计算
- 不再有时间步依赖
- 训练从 O(n) 串行 → O(1) 层级并行
长距离依赖是怎么解决的?
靠 Self-Attention 为核心的一组组件协作完成:
- Self-Attention:任意两个位置一步直连
- Multi-Head Attention:不同 head 专门学不同远程关系
- Residual + LayerNorm:远程信息和梯度不易消失
- Positional Encoding:让“远近”有意义
一句话总括:Self-Attention 让所有位置直接互相看到,从而同时解决并行计算和长距离依赖问题。
二、输入不是「文字」,而是状态向量
1. Token 与 Tokenizer
模型不直接处理字符或词语,而是处理 token。输入文本首先经过 tokenizer,被切分为 token_id 序列。
现代 tokenizer 采用子词或字节级策略(BPE、WordPiece、Unigram、Byte-level BPE),核心原则是:
任何输入字符最终都能被表示成 token_id 序列。
即使遇到生僻文字或罕见字符,tokenizer 也不会「找不到词表」,而是退化为更细粒度的子词甚至 UTF-8 字节表示(代价是 token 数变多)。
词表中允许存在重叠 token(如「我 / 非常 / 喜欢 / 非常喜欢」同时存在),但一次分词只选择一条最优切分路径,不产生冗余。
2. Token Embedding
token_id 通过 embedding 矩阵映射为向量:
1 | token_id → embedding ∈ R^d |
三个关键事实:
- token_id 是固定的索引
- embedding 向量是可训练参数
- embedding 的具体值在训练过程中不断学习更新
embedding 不是人为定义的语义,而是完全数据驱动学出来的状态表示。
3. 位置编码:为什么必须有?
Attention 的核心计算基于内容相似度,本身不关心顺序。如果不引入位置信息:
「我 喜欢 你」与「你 喜欢 我」在 Attention 看来只是同一组 token 的不同排列。
这在数学上对应 Attention 的置换等变性(Permutation Equivariance):重排输入只会导致输出对应重排,不会产生「顺序语义」。
但语言、时间序列、音频、代码都是顺序敏感的,因此必须引入位置信息。
常见方式:
- 可训练的位置 embedding
- 正弦位置编码
- RoPE、ALiBi 等相对位置机制
需要特别指出:
位置编码在训练和推理中都参与 forward 计算
只是有些实现把位置作为参数存储,有些作为计算规则存在
位置编码不是「知识」,而是 Transformer 理解序列的坐标系。
三、Attention:可学习的信息路由机制
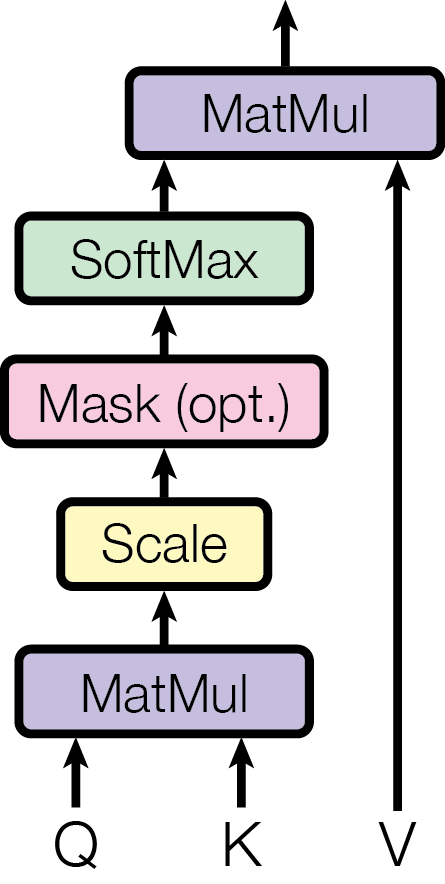
1. Q / K / V 的定义
给定某一层的输入状态
关键点:
是参数矩阵 - 对所有 token 共享
- Q / K / V 是运行时动态计算的
模型不保存「每个 token 的 Q/K/V 表」,而是保存「如何从任意状态映射到 Q/K/V 的规则」。
核心理解:
Q / K / V 本质是同一个 token 在不同「视角空间」的表示。
Attention 的计算过程 = 用 Query 空间去 Key 空间里做相似度搜索,再把 Value 空间的信息加权汇总。
从语义角色看:
- Query:查询目标(「我在找什么」)
- Key:匹配索引(「我能被什么找到」)
- Value:传递信息(「我要传递什么内容」)
这是典型的内容寻址(content-based addressing)。
为什么要分离 Q / K / V?
如果用同一向量同时表示「查询需求」「匹配标识」「传递内容」,会导致:
- 表达能力受限:查找规则和信息内容被绑定
- 优化困难:一个维度的变化同时影响三种语义角色
- 学习粗糙:无法独立学习不同的关系模式
分离后的优势:
- 解耦需求与内容:不同维度专门用于「问问题」(Q)、「当索引」(K)、「装内容」(V)
- 更高表达自由度:使 Attention 从简单的「相似度混合」升级为「可学习的信息检索」
- 稳定的优化路径:三个投影矩阵可独立学习
2. Attention 的计算公式
这一过程:
- 用 Q 和所有 K 做相似度匹配
- softmax 得到注意力权重分配
- 对 V 做加权求和完成信息汇聚
这正是「状态之间的信息路由」。
公式背后的设计逻辑
为什么是
点积计算向量相似度:
score[i, j] = Q_i · K_j^T
= Σ (d = 1 → d_k) Q[i, d] × K[j, d]
- 若
和 方向一致(需求匹配),点积大 - 若方向不一致,点积小甚至为负
- 点积满足:可微、高效(GPU 友好)、在高维空间稳定
这是典型的基于内容的相似度匹配。
为什么除以
这是数值稳定性问题。当维度
- 点积的方差随维度线性增长
- 导致 softmax 输入值过大,迅速饱和
- 梯度接近 0,难以训练
通过
为什么用 softmax?
softmax 提供三个关键性质:
- 所有权重 ≥ 0
- 所有权重和 = 1(归一化的概率分布)
- 可微且梯度稳定
这使注意力权重具有明确的概率解释:「当前 token 有 60% 在看 A,30% 在看 B,10% 在看 C」。
为什么最后乘 V?
因为
1 | output[i] = Σ_j α[i, j] · V[j] |
其中
3. Self-Attention 与 Cross-Attention
Self-Attention 的定义
Self-Attention 的核心特征:Q、K、V 都来自同一条序列(同一组状态)。
这里
- 同一批 token
- 既提问(Query)
- 又被提问(Key)
- 又提供信息(Value)
可理解为:序列「对自己」做 Attention,是序列内部的信息路由与整合。
Cross-Attention(交叉注意力)
在 Encoder-Decoder 架构中:
- Query 来自 Decoder
- Key 和 Value 来自 Encoder
这是 Decoder 「对 Encoder 做 Attention」,用于对齐两个不同序列。
对比总结
| 类型 | Q 来源 | K/V 来源 | 用途 |
|---|---|---|---|
| Self-Attention | 同一序列 | 同一序列 | 序列内部信息整合 |
| Cross-Attention | Decoder | Encoder | 跨序列信息对齐 |
| Masked Self-Attention | 同一序列 | 同一序列(带因果 mask) | 自回归生成 |
Self-Attention 的设计意义
Transformer 选择 Self-Attention 作为核心机制,有三个关键优势:
- 打破顺序依赖:不像 RNN 需要逐步处理,可全局并行计算
- 任意两点直接交互:第 1 个 token 可直接关注第 1000 个 token,路径长度为 1
- 对称、通用、可扩展:不假设语法结构、不假设距离关系,所有结构由数据驱动学习
核心直觉:
可把序列想象成一群人在讨论:
- 每个人既听别人说话,又被别人听
- 没有「外部信息源」,所有信息都在这群人之间流动
- 这就是 「Self」 的含义——序列内部的自我关联
Masked Self-Attention
Decoder 中使用的 Masked Self-Attention 仍是 Self-Attention,只是增加了约束:
- 每个位置只能看到之前的位置(因果 mask)
- 但 Q、K、V 依然来自同一序列
因此:Masked Self-Attention = 带因果约束的 Self-Attention
四、Multi-Head:并行的关系子空间
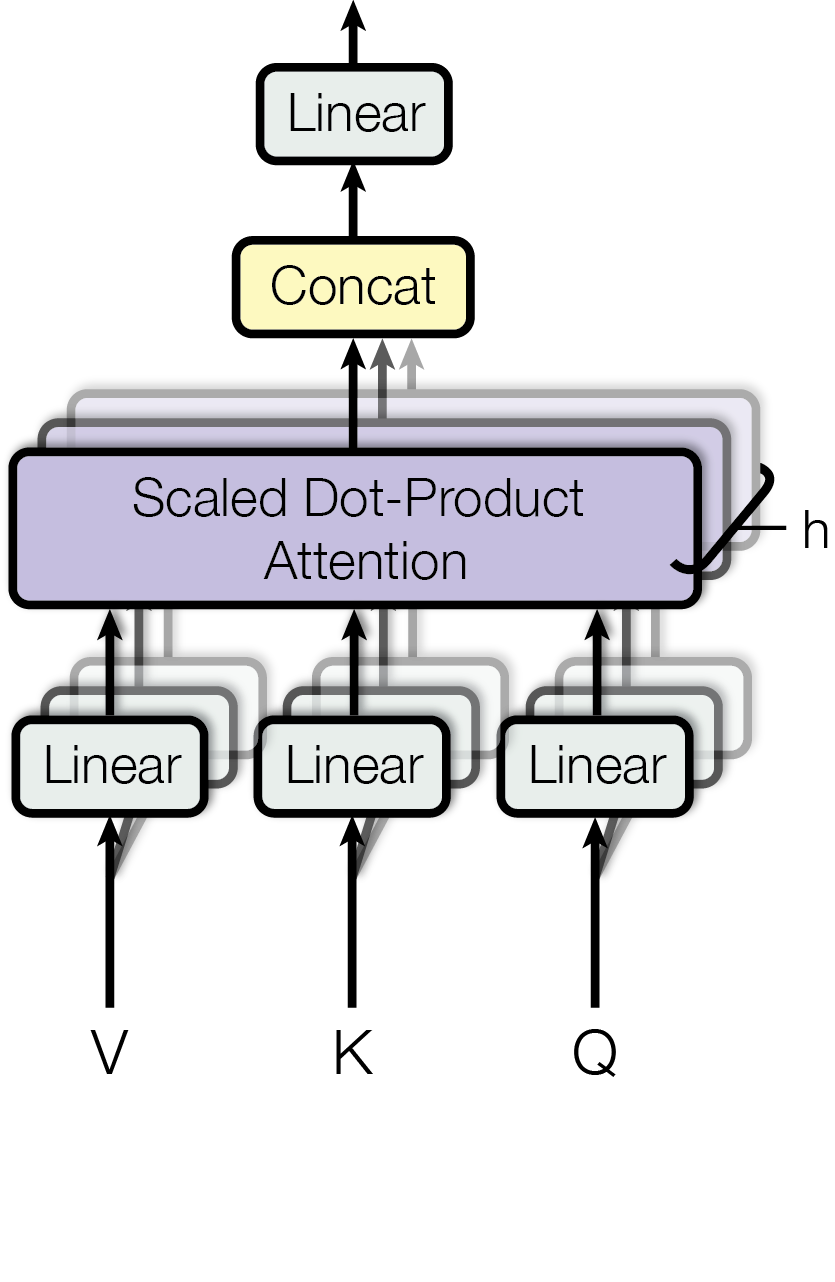
基本原理
Multi-Head Attention 不是「多算几次同样的 Attention」,而是:
- 每个 head 有自己的
- 从同一输入状态投影到不同子空间
- 在不同子空间中学习不同关系模式
实现上通常把
子空间的具体实现
假设
实现方式(不是 8 套完全独立的小 Attention):
- 一次性线性投影:
- Reshape:
,分配给 8 个 head - 每个 head 独立计算 Attention
- Concat +
融合
「子空间」的含义:
- 不是人工预先指定的「语法子空间」或「语义子空间」
- 而是:同一输入在不同线性投影下,被映射到不同方向的表示空间
- 每个 head 有独立的
,天然定义了不同子空间
为什么不能直接 concat?
因为:
- 每个 head 只在低维子空间中工作
- concat 只是简单拼接,不同 head 之间没有交互
- 缺少信息融合机制
- 信息融合:把多个 head 的结果线性混合,允许 head 之间交互
- 维度映射:将拼接后的向量映射回
,以便与残差连接相加 - 输出投影:作为 Attention 层真正的「输出投影层」
可将
为什么每一层都要自己的
因为不同层关注的关系层级不同:
- 底层:偏局部、句法关系
- 高层:偏语义、抽象关系
每一层的「信息融合方式」应该不同,所以每层都有独立的
不同 Head 如何实现分化?
Multi-Head Attention 没有显式的互斥机制来强制不同 head 学习不同模式。那为什么它们通常不会学成完全一样?
三种隐式分化机制
1. 参数初始化的差异
每个 head 的
- 优化轨迹不同
- 早期梯度方向不同
- 进入不同的局部最优区域
2. 路径依赖的梯度更新(核心机制)
这是最关键的分化压力:
- 每个 head 接收到的梯度,取决于它当前「已经在关注什么」
- 一旦 head 之间产生微小差异,梯度会放大这种差异,而非抹平
- 优化是路径依赖的:不同的 attention pattern → 不同的梯度信号 → 进一步分化
例如,即使两个 head 都偏向「长距离依赖」,它们可能分别专注于:
- head A:句法长距离(主语-谓语跨句)
- head B:指代长距离(代词-先行词)
Attention pattern 不同 → 对 loss 的贡献路径不同 → 梯度方向不同 → 继续分化
3.
所有 head 的输出最终通过
- 模型的最终 loss 只关心「哪些 head 的信息真的有用」
- 若两个 head 提供高度相似的信息,对 loss 的边际贡献是冗余的
- 梯度会倾向于:强化其中一个,让另一个转向其他有用方向
- 这是隐式的多样性压力:冗余 head 是「浪费参数」,优化倾向于减少浪费
Head 分化的实际表现
在训练好的语言模型中,常见现象:
- 某些 head 专注局部依赖(相邻 token)
- 某些 head 专注长距离依赖
- 某些 head 偏向句法关系(主谓宾)
- 某些 head 偏向指代关系(he/she/it)
没有任何硬编码规则,这些模式都是训练自发形成的。
Head 冗余现象与过参数化设计
需要指出:Multi-Head Attention 确实会出现冗余。
已知现象:
- 多个 head 可能学到非常相似的 attention pattern
- 某些 head 几乎「没在干活」
- Head 利用率不均
实验证据:
- 论文表明:可剪掉相当一部分 head,性能几乎不变
- Head pruning(头剪枝)后的模型:参数更少、推理更快、性能基本不降
这说明:Multi-Head Attention 在实践中是过参数化的。
为什么接受过参数化?
过参数化是特性,不是 bug
- 让优化更容易
- 给模型更多「自组织」的自由度
- 降低了设计者必须「手工指定结构」的需求
显式互斥约束反而可能伤性能
- 历史上有人尝试过:强制 head 正交、去相关 loss、specialization 正则项
- 结果往往是:训练更难、收敛更慢、泛化未必更好
- 原因:模型「知道自己该怎么分工」,人为强行规定反而限制了自由度
核心理解
Multi-Head Attention 是一种「软分工、自发组织」的机制:
- 没有显式互斥机制来防止多个 head 学到相似模式
- 通过参数初始化差异、路径依赖的梯度更新、输出融合层的隐式竞争,在实践中形成自发分工
- 这种结构是刻意过参数化的,允许一定程度的冗余,而非强制最优分解
- Head 数量(8、16、32、64)是超参数,代表并行关系建模的容量上限,而非「关系类型数」
五、FFN:状态内部的非线性变换
Attention 完成了「信息路由」——决定了从哪里汇聚信息。但汇聚后的信息如何变换?这就是 FFN 的职责。
FFN 的结构
核心特征:
- 逐 token 计算:对序列中每个 token 独立应用同一套参数
- 参数共享:所有位置使用相同的
- 无交互性:token 之间不发生信息交换
- 强非线性:通过激活函数
引入非线性变换 - 升维-压缩:通常先升维(如 4×d)再降维
典型配置:
(升维,通常 ) (降维) :激活函数(ReLU、GELU、SwiGLU 等)
为什么 Attention 本身不够?
Attention 的核心输出是:
这是线性加权和。即使注意力权重
线性操作的局限:
- 不能创造新特征
- 不能做复杂的特征组合
- 不能实现条件逻辑(「A 且 B」这类组合)
深度学习的基本原理:没有非线性,深度网络再深也等价于一个线性变换。
FFN 为什么能「重塑表示」?
1. 非线性激活打破线性限制
激活函数
2. 升维 → 非线性 → 压缩 = 特征重组
可将 FFN 理解为:
- 展开:将 token 表示投影到高维空间(
) - 变换:在高维空间进行非线性「切割」和「门控」
- 压缩:再投影回原空间(
)
这允许模型学到:
- 高阶特征组合:复杂的特征交互模式
- 条件激活:某些特征只在特定上下文中生效
- 抽象语义方向:更高层次的语义表示
Attention 与 FFN 的分工
这两个组件在 Transformer 中扮演互补角色:
Attention:负责「关系建模」
- token 之间可以交互
- 决定「看谁」
- 完成信息汇聚
FFN:负责「表达变换」
- token 之间不交互
- 决定「变成什么」
- 完成信息重组
直观比喻:
把序列想象成一排学生:
- Attention 阶段:学生之间讨论、互相参考答案
- FFN 阶段:每个学生回到座位,用同一套规则独立思考
没有学生和旁边的人交流,但大家使用的是同一本「公式书」(共享参数)。
「逐 token」的精确含义
关键点:FFN 不让 token 之间交互。
如果有序列
特征:
- ✔ 每个 token 独立计算
- ✔ 参数共享(同一套
) - ✔ 可完全并行(所有 token 同时计算)
- ❌ token 之间 无信息交换
这种设计有三个优势:
- 解耦职责:Attention 专注关系,FFN 专注变换
- 高效并行:所有位置可同时计算
- 增强非线性:每个 token 都经历完整的非线性变换
这种设计实现了关系建模与表示变换的解耦,两者各司其职又相辅相成。
如果没有 FFN 会怎样?
如果只堆叠 Attention + Residual,而没有 FFN:
- 整个网络退化为多次线性混合
- 表示空间无法被真正「变形」
- 模型退化成复杂的线性滤波器
- 表达能力严重受限,无法逼近复杂非线性函数
实验和理论都表明:FFN 是 Transformer 表达能力的关键来源。
六、Residual 与 LayerNorm:深度可训练性的关键
为了让多层堆叠可行,Transformer 使用了两项关键技术:
- 残差连接(Residual Connection):防止信息退化,允许深层网络
- LayerNorm:稳定数值分布,避免训练崩溃
现代模型几乎全部采用 Pre-LN 结构以增强稳定性。
这两项技术不是 Transformer 的创新,但它们对于构建深层网络至关重要。没有它们,Transformer 无法堆叠到几十层甚至上百层。
七、Transformer Block:整体架构
现在已经理解了所有核心组件,可以看看它们如何组织成完整的架构。
Block 的基本结构
无论 Encoder 还是 Decoder,Transformer 的核心都是反复堆叠同一种 Block。典型结构:
- Multi-Head Self-Attention
- Residual + LayerNorm
- Position-wise FFN
- Residual + LayerNorm
Transformer 本质就是:这个 Block 堆叠 N 次。
N 取决于模型规模,从十几层到上百层不等。
信息流动的完整路径
在每个 Block 中:
- Attention 阶段:通过 Self-Attention 完成信息路由,让每个 token 从其他 token 汇聚相关信息
- 残差连接:保留原始信息,防止信息丢失
- LayerNorm:稳定数值分布
- FFN 阶段:对汇聚后的信息进行非线性变换,重塑表示
- 再次残差 + LayerNorm:稳定输出
这个过程反复进行 N 层,逐步抽象和精炼信息。
Encoder vs Decoder
Encoder:
- 可看到完整输入序列
- 没有因果 mask
- 输出的是「被充分理解后的表示」
- 典型应用:文本理解、分类、检索向量(BERT)
Decoder:
- 使用 Masked Self-Attention(因果 mask)
- 每个位置只能看到之前的位置
- 用于自回归生成
- 典型应用:语言模型(GPT)
Encoder-Decoder:
- Decoder 中额外包含 Cross-Attention 层
- 用于对齐两个序列(如机器翻译)
- 典型应用:T5、BART
为什么大模型几乎都是 Decoder-only?
因为大模型的核心训练目标是自回归语言建模:
而互联网数据天然是连续文本流,不是严格的输入/输出对。Decoder-only:
- 目标函数最简单
- 数据利用率最高
- 工程实现最统一
- 推理与 KV Cache 高度契合
因此成为通用大模型的事实标准。
八、训练与推理:模型到底在「存什么」?
1. 模型参数存储的内容
训练完成后,模型保存的是:
- token embedding 矩阵
- 各层的
- FFN 参数(
) - LayerNorm 参数
- 输出层参数(
)
Q/K/V 本身不是参数,只是中间计算结果。
模型保存的是「规则」而非「结果」——保存的是如何计算 Q/K/V 的权重矩阵,而非每个 token 的具体 Q/K/V 值。
2. 推理过程概览
推理时,模型以自回归方式反复执行:
- 当前 token 序列 → forward
- 预测下一个 token 的概率
- 采样或选择 token
- 拼接到序列末尾
- 重复
上下文长度始终等于:
输入 token 数 + 已生成 token 数
hidden states 是中间变量,不算 token,不占上下文长度。
3. 完整推理流程详解
以 Decoder-only 模型(如 GPT)为例,假设当前输入序列为 [x₁, x₂, ..., xₜ]:
第 1 步:Embedding + 位置编码
得到第 0 层(输入层)的隐状态矩阵:
第 2 步:逐层 Transformer Block
对第
LayerNorm(Pre-LN)
计算 Q/K/V
Masked Self-Attention(每个位置只能看到之前的位置)
Multi-Head 融合
残差连接
FFN + 残差
第 3 步:提取最后一个 token 的表示
因为语言模型的目标是预测:
第 4 步:映射到词表(LM Head)
第 5 步:采样下一个 token
通过采样策略(greedy、top-k、top-p、temperature)得到:
第 6 步:拼接并重复
将新 token 加入序列:[x₁, x₂, ..., xₜ, x_{T+1}],然后重新执行整个 forward 过程。
关键理解:推理不是「在同一个 forward 里不断计算」,而是每次 forward 只预测一个 token,然后将其接到序列后面再完整计算一遍(或使用 KV Cache 加速)。
4. KV Cache:推理加速的关键优化
在生成第
因此在推理阶段:
- 历史 token 的 K/V 被缓存
- 新 token 只需计算一次 K/V
- Attention 直接使用缓存 + 新值
KV Cache 不是新结构,而是 Attention 在推理阶段的缓存优化,使生成从反复重算历史变为高效增量计算。
什么是「历史 token」?
在自回归生成中:
历史 token = 当前这一步之前,已经确定下来的所有 token
包括两部分:
- 最初输入的 prompt token
- 之前步骤中模型生成并已接纳的 token
生成过程示例
假设输入 prompt:[我, 喜欢]
第 1 步:预测第 3 个 token
- 当前序列:
[我, 喜欢] - 历史 token:
[我, 喜欢] - 它们的 K/V 被计算并缓存
- 预测出:
吃
- 当前序列:
第 2 步:预测第 4 个 token
- 当前序列:
[我, 喜欢, 吃] - 历史 token:
[我, 喜欢, 吃](注意「吃」已成为历史) - 只需为「吃」计算新的 K/V 并追加到缓存
- 预测出:
苹果
- 当前序列:
第 3 步:预测第 5 个 token
- 当前序列:
[我, 喜欢, 吃, 苹果] - 历史 token:所有 4 个 token
- 只为「苹果」计算新 K/V
- 当前序列:
Token 实例 vs Token 类型
关键区分:
- Token 类型(token_id):tokenizer 层面的概念,如「我」的 token_id 可能是 1234
- Token 实例(token occurrence):序列中特定位置的 token,即使 token_id 相同,不同位置也是不同实例
为什么相同 token_id 的 K/V 也不同?
假设序列是:[我, 喜欢, 我]
两个「我」虽然 token_id 相同,但:
位置不同
上下文不同(这是更关键的原因)
- 第 1 个「我」只能看到自己
- 第 3 个「我」能看到
[我, 喜欢, 我] - Attention 结果完全不同
因此 K/V 不同
由于
,所以 ,
KV Cache 的精确含义
Transformer 不关心「这个 token 是否重复出现」,只关心「这是序列中的第几个位置」。
KV Cache 缓存的是:
- 某一层、某一 head、某一位置的 K 和 V
- 不是某一 token_id 的 K/V
缓存结构:[(pos=1, token=我), (pos=2, token=喜欢), (pos=3, token=我)]
每个位置都是独立的 token 实例,即使 token_id 重复。
历史 K/V 「不会改变」的含义
在推理阶段(参数固定的前提下):
- 某个 token 实例一旦被计算过,它在该层的 K/V 就完全确定
- 后续生成步骤中不会再修改这些缓存值
- 新生成的 token 会计算新的 K/V 并追加到缓存中
这就是为什么 KV Cache 能大幅加速推理:避免了对历史 token 的重复计算。
Context Window 的本质
为什么 context window = 输入 + 输出?
推理时模型每生成一个 token,就把它追加到序列末尾继续处理。KV Cache 里存的历史 token 包含 prompt + 已生成的输出,两者在结构上完全对等,共享同一块容量。所以上限不是”输入上限”,而是”输入 + 已生成输出的总序列长度上限”。
Context Window 大小由三个因素串联决定:
位置编码方案(架构层)— 决定能否超出训练长度
- 绝对位置编码:训练多长就只能用多长,超出直接崩
- RoPE(GPT/Claude 主流方案):位置用旋转角度编码,有规律可外推,能在训练长度基础上扩展,但外推越远质量下降
训练序列长度(训练层)— 基础能力的下限
- 模型实际见过的最长序列,是 context 建模能力的基准
- RoPE 可以在这个基础上外推,但不能无限延伸
显存/部署资源(推理层)— 实际使用的硬上限
- KV Cache 随 context 长度线性增长,显存不够就跑不了长 context
- 同一个模型,服务商和本地部署能用的 context 长度可能差几倍
对外公布的 Context Window = min(位置编码外推极限, 训练长度, 显存上限)
例如 Claude 200K、GPT-4 128K,都是综合三个因素后的对外承诺值。本地显存不够,实际能用的可能只有 32K。
九、设计哲学:演化与涌现
经过前面的技术细节,现在可以从更高层次理解 Transformer 的设计哲学。
演化而非推导
需要强调一个常被忽视的事实:
Transformer 并不是从第一性原理必然推导出的最优结构,而是在数学约束、工程约束和实验验证下,逐步演化出来的高度有效的架构。
其设计逻辑可以概括为:
- 目标是表达能力:所有数学结构(Attention、FFN、Multi-Head 等)共同构造一个高表达力、可优化的函数空间
- 训练填充能力:通过大规模数据和梯度下降,让参数收敛到该空间中能有效建模数据分布的区域
- 推理是涌现结果:所谓的「推理能力」不是显式编程的,而是模型在训练后自然呈现的行为模式
核心洞察
现代深度模型不是在「显式地教模型如何推理」,而是构造一个足够大、足够灵活的函数空间,让「推理能力」作为训练后的自然涌现结果出现。模型学到的是「在什么样的上下文下,下一个 token 的条件分布是什么」,而不是「如果 A 且 B,则推出 C」这样的显式逻辑规则。
这意味着:
- Transformer 的各个组件共同构成一个可学习的表示空间,而非独立的「智能模块」
- 每个「数学技巧」(LayerNorm、Residual、缩放、softmax)本质都是在让训练能够找到好解
- 结构的有效性来自:表达力(能表示什么)+ 可优化性(能不能学到)+ 工程可行性(能不能实现)的综合平衡
三层架构的本质
Transformer 的成功来自三层要素的协同:
第一层:函数空间(结构设计)
- Attention:决定状态如何互相连接
- FFN:决定状态如何非线性变换
- Multi-Head:决定并行关系容量
- → 这一层决定了「能表示什么」
第二层:优化可达性(数学与工程)
- LayerNorm、Residual:稳定训练
- 参数初始化、缩放技巧:控制数值
- 自回归目标:简化优化
- → 这一层决定了「能不能学到」
第三层:数据分布(语义与行为)
- 语言结构、逻辑模式
- 世界知识、推理痕迹
- 人类文本中的统计规律
- → 这一层决定了「学成什么样」
关键洞察:所谓的「推理能力」不在任何一层内部,而是在三层叠加后的整体行为上自然涌现。
设计的演化本质
Transformer 的诞生过程可以理解为四重约束下的结构搜索:
- 可微约束:必须端到端可训练、能在 GPU 上高效计算
- 表达约束:必须能表示足够复杂的函数、能够 scale
- 工程约束:必须并行友好、易于分布式训练
- 实验约束:必须在当时的计算资源和数据规模下表现明显更好
这不是演绎推理的结果,而是一种受约束的经验演化过程——更像生物进化、工程设计,而非形式逻辑证明。
许多看起来「有道理」的解释,实际上是事后合理化:结构先被实验验证为有效,理论解释是在「理解为什么它能活下来」。这是典型的科学路径:先发现 → 再解释 → 再抽象 → 再指导下一轮设计。
从结构到能力的涌现
核心理念:
现代深度模型的设计,本质上不是在「显式地教模型如何推理」,而是:
- 构造一个高表达力、可优化的函数空间
- 让训练过程在大规模数据的约束下,将参数收敛到该空间中的某个有效区域
- 从外部观察,这种函数行为呈现出类似推理、理解与规划的能力
这意味着:
- 模型没有「推理模块」,它只是学到了一个在训练分布上表现得「像在推理」的函数
- 推理是外部观察者给出的解释,不是模型内部的显式过程
- 能力的涌现依赖于:结构设计允许的表达空间 × 数据分布蕴含的模式 × 优化过程能够到达的区域
结语:Transformer 的最终抽象
技术层面的总结
Transformer 是一种以 token 为单位的序列建模框架:
- 通过 Attention 实现可学习的全局信息路由
- 通过 FFN 实现逐 token 的非线性状态变换
- 通过多头并行建模不同关系子空间
- 依靠残差与归一化稳定深度训练
- 在 Decoder-only 形态下以自回归方式逐步生成输出
- 所有长期知识存于参数中,短期上下文由 token 序列动态提供
理解的三个层次
理解 Transformer,有三个层次:
- 技术层次:知道每个组件是什么、怎么算
- 原理层次:理解为什么需要这些组件、它们解决什么问题
- 哲学层次:认识到这些结构不是理论推导的必然,而是在约束空间中探索的产物
当开始思考「为什么是这个结构而不是别的」时,认知就从第二层进入了第三层。
这一思考过程本身就是深入理解的标志——它意味着不再将 Transformer 视为完美的理论大厦,而是理解其本质:在当前认知、资源和工程能力约束下,演化出的一条可行且有效的路径。
Transformer 的成功,本质上是:在正确的约束下,允许了正确的涌现。