以下内容由AI辅助生成
神经网络训练的过程,看起来是在“学习语义”或“理解结构”,但在更底层,它其实是一件非常朴素的事情:
一层一层地传递和变换数字。
而几乎所有训练不稳定、梯度异常、不收敛的问题,最终都可以归结为一个原因:
中间数值的尺度失控了。
LayerNorm(Layer Normalization)正是为了解决这个问题而出现的。但要真正理解它,不能从公式开始,而必须先回到一个更基础的问题:什么是归一化,神经网络为什么需要归一化。
一、什么是“归一化”:先抛开神经网络
先从一个生活中的例子出发。
假设你要比较两次考试成绩:
- 一次考试满分 150
- 另一次考试满分 100
你不能直接比较 120 分和 80 分谁更好,因为它们的尺度不同。
一个更合理的做法是:
- 减去平均值
- 再除以标准差
这样得到的数值不再依赖原始分数范围,而只反映相对水平——平均值约为 0,波动程度约为 1。
这就是归一化(Normalization)的本质思想:
不改变相对差异,只统一数值尺度。
二、神经网络为什么必须做归一化
回到神经网络。神经网络的基本操作是反复进行线性变换:
如果输入
当层数不断增加时:
1 | x → y → z → u → … |
哪怕每一层只“放大或缩小一点点”,结果也会变成:
- 激活值越来越大(数值爆炸)
- 或越来越小(数值消失)
这就像一张图片被反复复印:复印次数一多,画面一定会失真。
于是,一个非常直接但极其重要的工程直觉出现了:
能不能在每一层之间,把数值拉回到一个“正常范围”?
这正是神经网络中各种 Normalization 方法存在的根源。
三、LayerNorm 到底在归一化什么
在 Transformer 中,每个 token 在某一层都会被表示成一个向量:
这
LayerNorm 的做法非常明确:
- 不看其他 token
- 不看 batch
- 只对当前这个 token 自己的向量做归一化
具体来说,它会在特征维度(hidden dimension)上计算均值和方差:
然后进行标准化,并加上可学习的缩放与平移参数:
归一化之后,向量的均值约为 0、方差约为 1,但通过
一句话总结:
LayerNorm 是对“每一个 token 自己的向量”做归一化,完全不依赖其他 token 或 batch。
四、为什么 Transformer 特别容易“数值失控”
理解了归一化之后,再看 Transformer 的结构,就会发现:它在数值层面上,天然是一个不稳定系统。
原因来自三个叠加的结构性因素:
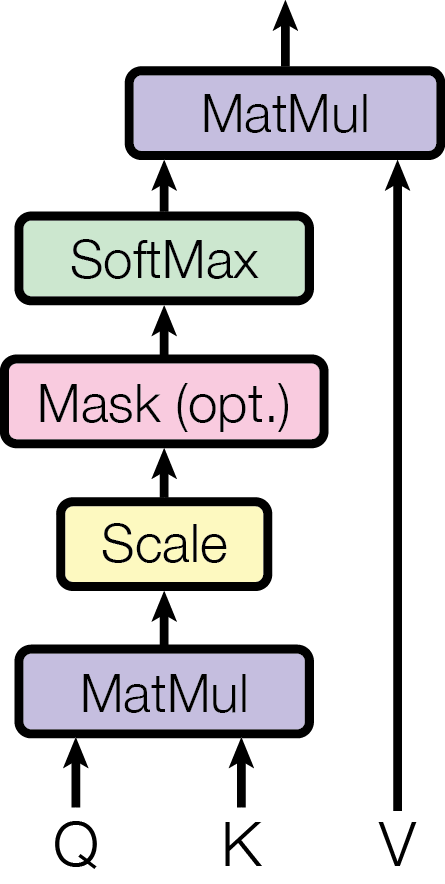
1. Attention 是不受约束的加权求和
Attention 的输出形式是:
它本质上是多个向量的线性组合,目标是混合信息,而不是控制输出尺度。缺少约束时,某些 head 的输出可能越来越大,某些维度可能长期主导,不同 token 的数值分布会逐渐漂移。
2. 残差连接会层层累加数值
Transformer 中每一层都有残差结构:
残差的作用是保证信息通路,但它也意味着新信息会不断叠加到旧表示上,数值会随着层数持续累积。
一个常见的误解是把 residual 当作“稳定器”。更准确的说法是:
Residual 负责信息通路,但并不负责数值稳定。
3. Softmax 对尺度极其敏感
Attention 内部使用 softmax,而 softmax 只在一个很窄的数值区间内工作得好:
- 输入过大 → 接近 one-hot → 梯度几乎为 0
- 输入过小 → 接近均匀分布 → 注意力失效
Transformer 同时包含 Attention 的加权求和、Residual 的数值累加、Softmax 的高敏感性——如果没有归一化,数值失控几乎是必然的结果。
五、LayerNorm 如何“救场”
LayerNorm 的作用可以概括为一句话:
在每一层,把每个 token 的表示拉回到同一个稳定的统计坐标系。
它在 Transformer 中的分工可以用这张图来理解:
1 | 输入 token 向量 x |
三者的职责是:
- Attention 管信息交流
- Residual 管信息传承
- LayerNorm 管数值纪律
LayerNorm 带来的直接效果包括:
- 各层输入分布保持相对一致
- 数值不再随层数漂移
- softmax 始终工作在有效区间
- 梯度能够稳定传播
因此可以说:
没有 LayerNorm,Transformer 在数学上是一个不稳定系统;有了 LayerNorm,它才成为可训练的深层模型。
六、为什么不用 BatchNorm
在讨论 LayerNorm 时,BatchNorm 经常被拿来对比。它们同属“归一化家族”,但适用场景完全不同。
BatchNorm 的核心思想是:
利用一个 batch 内所有样本的统计量来做归一化。
这在 CNN 中非常合理(输入尺寸固定、batch 结构稳定),但在 Transformer / NLP 中,会遇到根本性冲突:
1. Batch 本身不稳定
- 句子长短不同
- padding 复杂
- 推理时常常 batch = 1
2. Token 不应被迫参考其他样本
Transformer 的设计是让 token 之间的交互只发生在 Attention 中,归一化阶段不应引入额外耦合。而 BatchNorm 恰恰会让一个 token 的数值受其他 token、其他样本影响。
LayerNorm 则完全相反:不看 batch、不看其他 token,只对自身状态做校准。
一句话总结区别:
BatchNorm 在“群体里”找尺度,LayerNorm 对“自己”做校准。
Transformer 需要的是后者。
结语:把 LayerNorm 放回正确的位置
LayerNorm 并不是 Transformer 的“附加技巧”,而是归一化思想在序列建模中的一次精准落地:
- 以 token 为基本单位
- 不依赖 batch
- 不混淆语义交互与数值校准
它让 Transformer 能在极深的结构中,始终保持数值可控、梯度可传、注意力可学习。