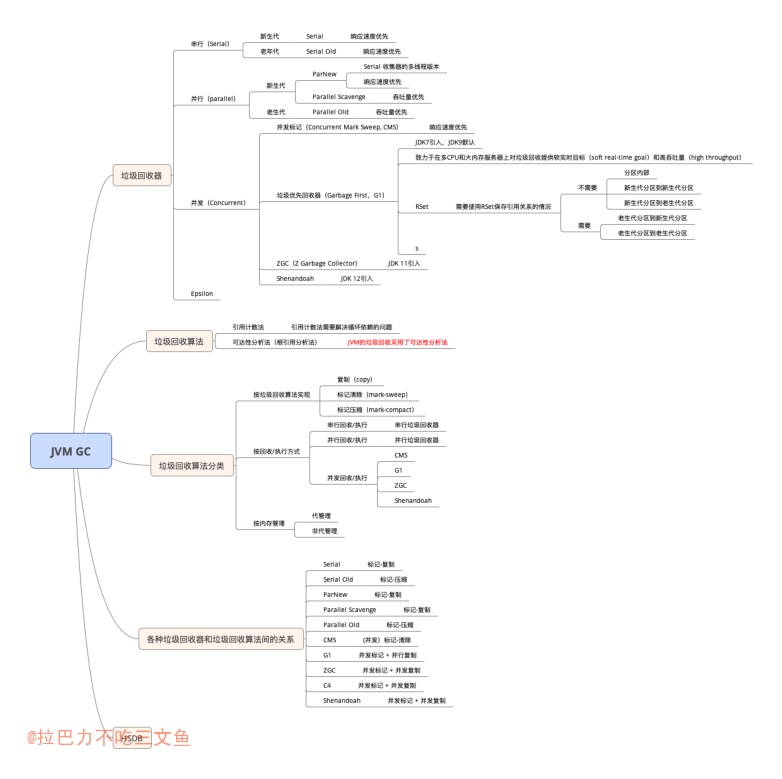
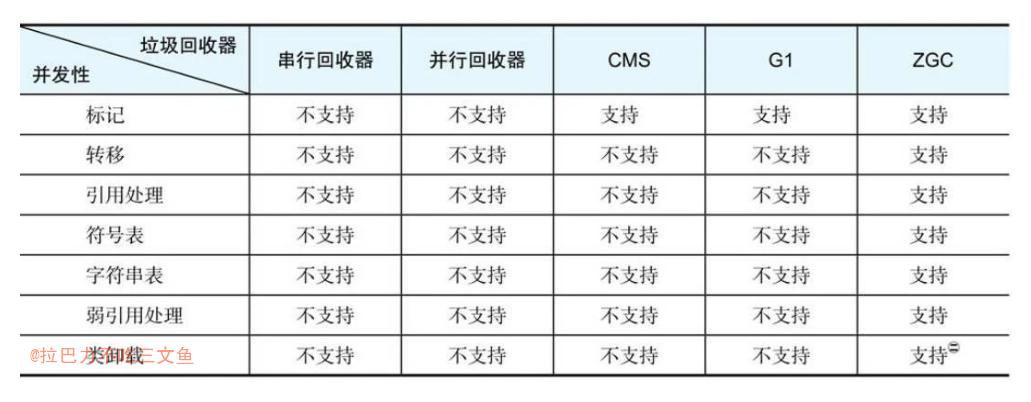
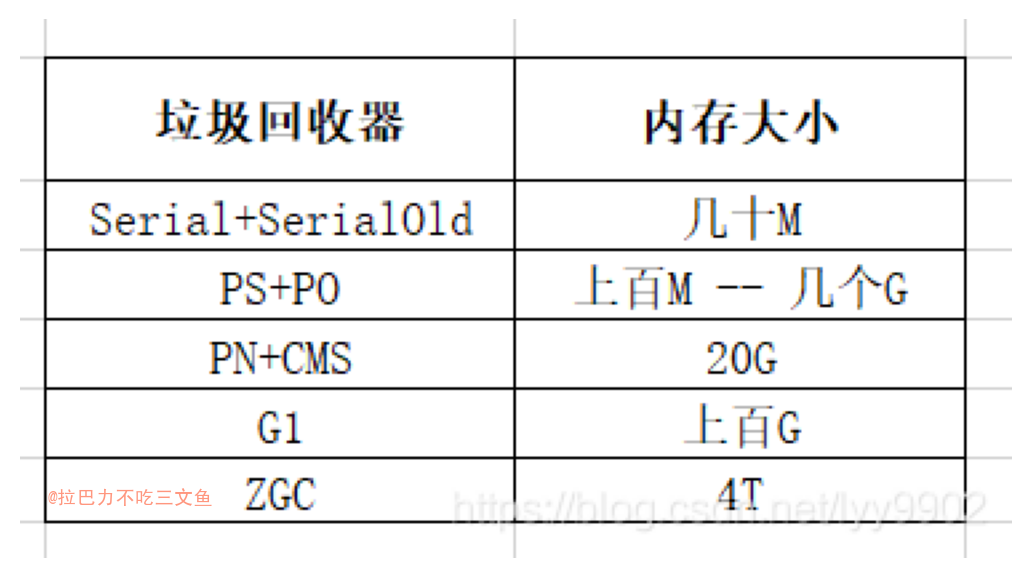
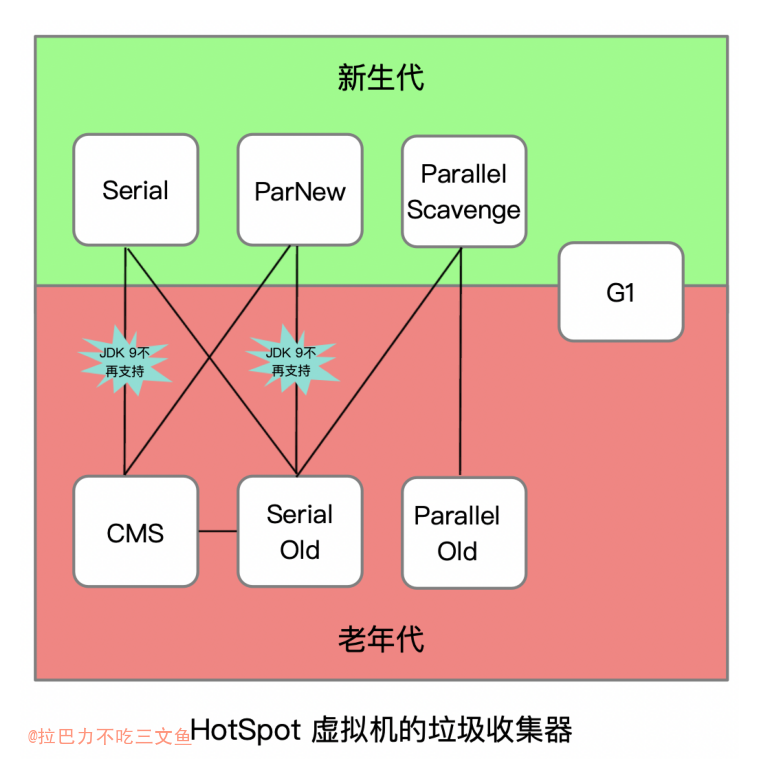
首先重温一个问题:RPC可以和事务绑定吗?
有以下业务场景:
- 用户扣钱成功之后,可以玩一局游戏;如果用户没成功玩游戏,需要将已扣的钱退回给用户。
服务架构:服务A(游戏服务),服务B(用户资产服务)。
游戏订单状态:1(初始状态);2(扣费成功);3(退费成功);4(不存在)
实现基本流程如下:
流程1:
玩游戏请求----------> 服务A [无事务] [1.插入游戏订单(订单状态:1)] [2.RPC进行扣费]------------------------------------------------>服务B [3.更新游戏订单状态(1-> 2)(DB操作)] (订单状态为2的可以参与游戏)
- 流程2 (针对扣费成功但超时返回的情况):
定时任务补偿----------> 服务A [无事务] [1.查询订单状态为1的订单] [2.RPC查询扣费订单是否存在]------------------------------->服务B [3_1.不存在 -- 更新游戏订单状态(1-> 4)(DB操作)] [3_2.存在 -- RPC取消扣费] ---------------------------------------->服务B [4.更新游戏订单状态(1-> 3)(DB操作)]
- 流程1 和 流程2 在并发执行的时候会存在 用户退费成功但仍然可以玩游戏的问题:
- 执行流程1中步骤2
- 执行流程2中步骤3_2
- 执行流程1中步骤3
解决方案1
- 加入订单时间校验:超过n分钟后的订单才允许退款(可以很大避免以上问题的发生,因为一个请求基本不可能执行几分钟还没结束)
定时任务补偿----------> 服务A
[无事务]
[0.查询订单状态为1的订单]
新增判断 - [1.查询订单创建时间是否超过n分钟,不满足暂不退款,中断执行]
[2.RPC查询扣费订单是否存在]------------------------------->服务B
[3_1.不存在 -- 更新游戏订单状态(1-> 4)(DB操作)]
[3_2.存在 -- RPC取消扣费] ---------------------------------------->服务B
[4.更新游戏订单状态(1-> 3)(DB操作)]
- 该方案的缺点
- 如果设置的订单退款超时时间太长,会导致用户被误扣的钱长时间未退款,引起投诉
- 设置足够合理的超时时间就一定能避免这个问题的发生了吗?不会存在极端情况,请求执行时间过长?
解决方案2
- 回到本文的标题。
- 通过和RPC绑事务的方式,也可以解决这个问题(不用通过配置时间差),本质是通过数据库锁的方式来解决。
定时任务补偿----------> 服务A
[1.查询订单状态为1的订单]
[2.RPC查询扣费订单是否存在]------------------------------->服务B
[3_1.不存在 -- 更新游戏订单状态(1-> 4)(DB操作)]
[新建事务]
[3_2.存在 -- 更新订单状态(1-> 3)(DB操作)]
[ if (row = UPDATE order SET status = 3 WHERE status = 1) > 0 ]
[4. RPC取消扣费] ---------------------------------------->服务B
[5_1. 调用成功 - 提交事务]
[5_1. 调用失败 - 异常回滚事务]
- 扣费的时候,update order set status = ’成功‘ where status = ’初始状态‘ ;update raw == 1 时, 执行RPC 冻结, 否则抛异常回滚事务
- 定时任务补偿退款的时候,update order set status = ’取消冻结成功‘ where status = ’初始状态‘ ;update row == 1 时, 执行RPC 取消冻结, 否则抛异常回滚事务
- 实际情况会比描述的复杂,因为status的最终值设置是根据RPC的结果来的,而不是一开始就能确定的;解决方案
- 新加字段,统一 update 未执行 到 已执行, 通过新字段来判断是否执行db成功
- select for update, 查的时候锁住该行数据
- 其他?
- 实际情况会比描述的复杂,因为status的最终值设置是根据RPC的结果来的,而不是一开始就能确定的;解决方案
解决方案3
- 方案1和方案2的结合
- 1分钟后才执行流程2退费
- 流程2中【3_1】 和【4】绑事务,【4】变成update order set status=3 where status=1
- 流程1中【3】,变成 update order set status=2 where status=1