以下内容基本都是从书籍中摘抄,用于个人记录
从AI得出的回答不一定正确或者只是现阶段暂时正确
增加部分个人理解
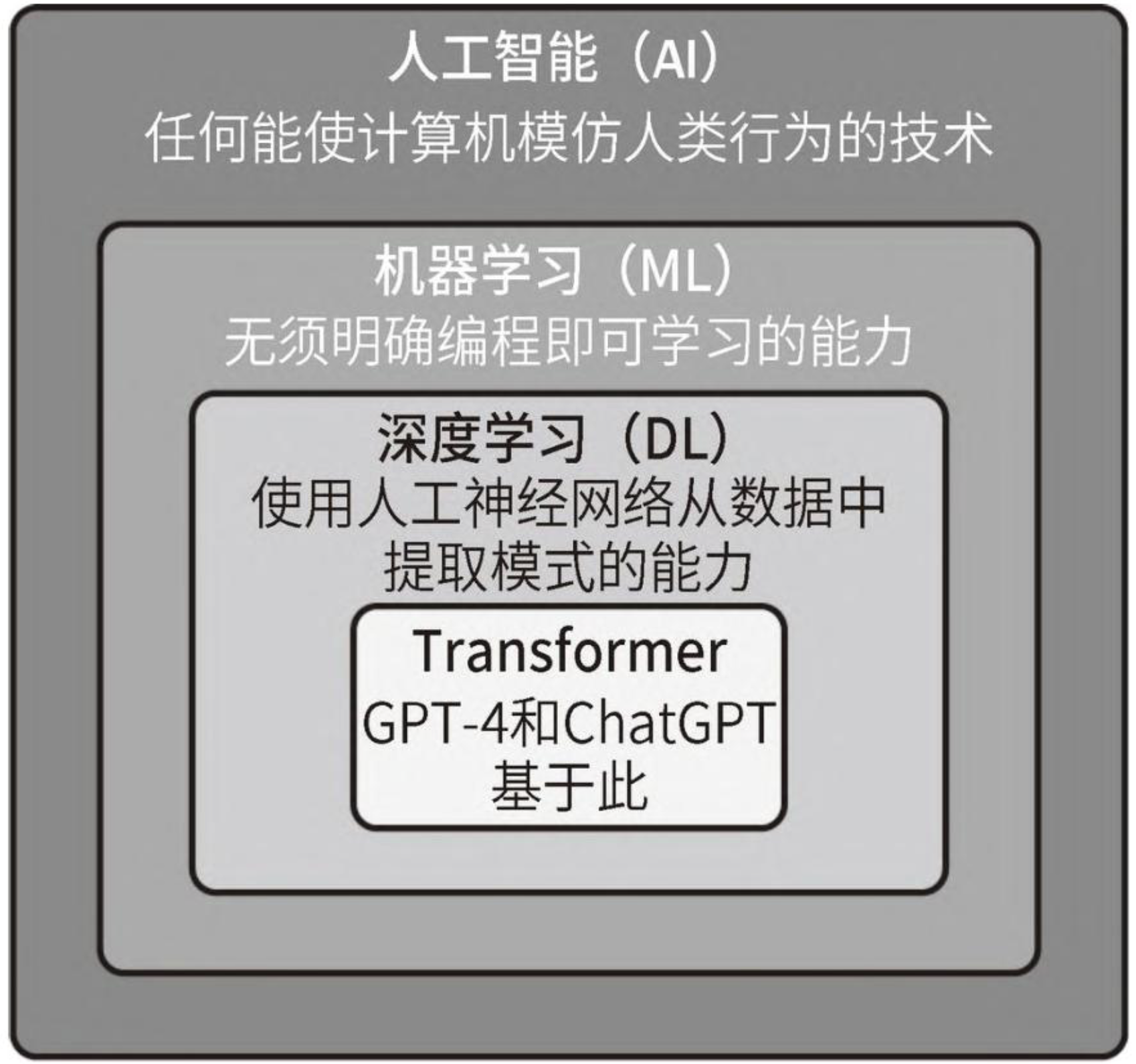
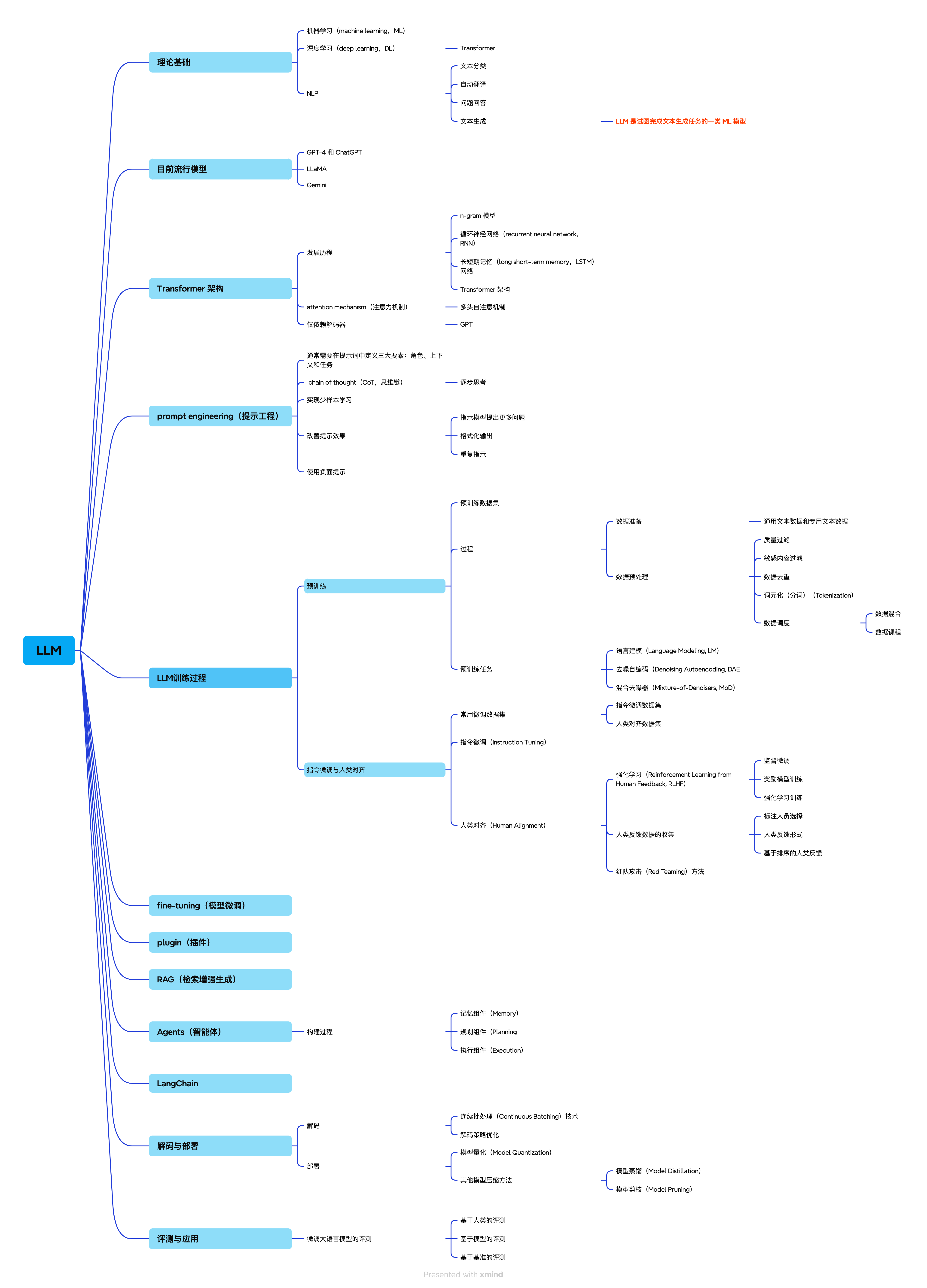
LLM(Large Language Model)
大语言模型的涌现能力被非形式化定义为“在小型模型中不存在但在大模型中出现的能力”,具体是指当模型扩展到一定规模时,模型的特定任务性能突然出现显著跃升的趋势,远超过随机水平。类比而言,这种性能涌现模式与物理学中的相变现象有一定程度的相似,但是仍然缺乏相应的理论解释以及理论证实,甚至有些研究工作对于涌现能力是否存在提出质疑 [38]。整体来说,涌现能力的提出有助于使得公众认识到大语言模型所具有的能力优势,能够帮助区分大语言模型与传统预训练语言模型之间的差异。
大语言模型的三种典型涌现能力。
- 上下文学习(In-context Learning, ICL). 上下文学习能力在 GPT-3 的论文中 [23] 被正式提出。具体方式为,在提示中为语言模型提供自然语言指令和多个任务示例(Demonstration),无需显式的训练或梯度更新,仅输入文本的单词序列就能为测试样本生成预期的输出。
- 指令遵循(Instruction Following). 指令遵循能力是指大语言模型能够按照自然语言指令来执行对应的任务 [28, 39, 40]。为了获得这一能力,通常需要使用自然语言描述的多任务示例数据集进行微调,称为指令微调(Instruction Tuning)或监督微调(Supervised Fine-tuning)。通过指令微调,大语言模型可以在没有使用显式示例的情况下按照任务指令完成新任务,有效提升了模型的泛化能力。相比于上下文学习能力,指令遵循能力整体上更容易获得,但是最终的任务执行效果还取决于模型性能和任务难度决定。
- 逐步推理(Step-by-step Reasoning). 对于小型语言模型而言,通常很难解决 涉及多个推理步骤的复杂任务(如数学应用题),而大语言模型则可以利用思维链(Chain-of-Thought, CoT)提示策略 [25] 来加强推理性能。具体来说,大语言模型 可以在提示中引入任务相关的中间推理步骤来加强复杂任务的求解,从而获得更 为可靠的答案。
通俗来讲,扩展法则与涌现能力之间微妙的关系可以类比人类的学习能力来解释。以语言能力为例,对于儿童来说,语言发展(尤其是婴儿)可以被看作一个多阶段的发展过程,其中也会出现“涌现现象”。在这一发展过程中,语言能力在一个阶段内部相对稳定,但是当进入另一个能力阶段时可能会出现重要的提升(例如从说简单的单词到说简单的句子)。尽管儿童实际上每天都在成长,但是语言的提升过程本质上是不平滑和不稳定的(即语言能力在时间上不以恒定速率发展)。因此,经常可以看到年轻的父母会对宝宝所展现出的语言能力进展感到惊讶。
这种大模型具有但小模型不具有的能力通常被称为“涌现能力”(Emergent Abilities)。为了区别这一能力上的差异,学术界将这些大型预训练语言模型命名为“大语言模型”
早期的语言模型主要面向自然语言的建模和生成任务,而最新的语言模型(如 GPT-4)则侧重于复杂任务的求解。从语言建模到任务求解,这是人工智能科学思维的一次重要跃升,是理解语言模型前沿进展的关键所在。
早期的统计语言模型主要被用于(或辅助用于)解决一些特定任务,主要以信息检索、文本分类、语音识别等传统任务为主。随后,神经语言模型专注于学习任务无关的语义表征,旨在减少人类特征工程的工作量,可以大范围扩展语言模型可应用的任务。
进一步,预训练语言模型加强了语义表征的上下文感知能力,并且可以通过下游任务进行微调,能够有效提升下游任务(主要局限于自然语言处理任务)的性能。随着模型参数、训练数据、计算算力的大规模扩展,最新一代大语言模型的任务求解能力有了显著提升,能够不再依靠下游任务数据的微调进行通用任务的求解。
大语言模型的能力特点:具有较好的复杂任务推理能力. 除了具有通用性外,大语言模型在复杂任务中还展现出了较好的推理能力。
大语言模型对科技发展的影响
- 【理论基础原理】尽管大语言模型技术已经取得了显著进展,但是对于它的基本原理仍然缺乏深入的探索,很多方面还存在局限性或者提升空间。首先,大模型中某些重要能力(如上下文学习能力)的涌现仍然缺乏形式化的理论解释,需要针对大语言模型基础能力的形成原因进行深入研究,从而揭示大语言模型内部的工作机理。
- 【细节公开和算力支持】其次,大语言模型预训练需要大规模的计算资源支持,研究各种训练策略的效果并进行可重复性的消融实验的成本非常高昂。学术界难以获得充分的算力来系统性研究大语言模型;虽然工业界或者大型研究机构不断推出性能优异的开源大模型,但是这些模型的训练过程的开源程度还不够充分,许多重要的训练细节仍缺乏公开的研究报道。
- 【人类对齐】第三,让大语言模型充分与人类价值观或偏好对齐也是一项重要的科研挑战。尽管大语言模型已经具有较好的模型能力,但是在特定场景下或者蓄意诱导下,仍然可能生成虚构、有害或具有负面影响的内容。这一问题随着模型能力的提升而变得更为难于解决。为了应对模型能力未来可能超越人类监管能力的情况,需要设计更为有效的监管方法来消除使用大语言模型的潜在风险。
- 随着大语言模型技术的迅猛发展,人工智能相关研究领域正发生着重要的技术变革
- 自然语言处理. 在自然语言处理领域,大语言模型可以作为一种通用的语言任务解决技术,能够通过特定的提示方式解决不同类型的任务,并且能够取得较为领先的效果。
- 信息检索. 在信息检索领域,传统搜索引擎受到了人工智能信息助手(即ChatGPT)这一新型信息获取方式的冲击。
- 计算机视觉. 在计算机视觉领域,研究人员为了更好地解决跨模态或多模态任务,正着力研发类 ChatGPT 的视觉-语言联合对话模型,GPT-4 已经能够支持图文多模态信息的输入。由于开源大语言模型的出现,可以极大地简化多模态模型的实现难度,通过将图像、视频等模态的信息与文本语义空间相融合,可以通过计算量相对较少的微调方法来研发多模态大语言模型。进一步,基于下一个词元预测的思路也可能会带来多模态领域的基础模型架构的转变,例如 OpenAI 最新推出的 Sora 模型就是基于图像块序列建模的思路进行构建的。
- 人工智能赋能的科学研究(AI4Science). 近年来,AI4Science 受到了学术界的广泛关注,目前大语言模型技术已经广泛应用于数学、化学、物理、生物等多个领域,基于其强大的模型能力赋能科学研究。
目前广泛采用的对齐方式是基于人类反馈的强化学习技术,通过强化学习使得模型进行正确行为的加强以及错误行为的规避,进而建立较好的人类对齐能力。
在实践应用中,需要保证大语言模型能够较好地符合人类的价值观。目前,比较具有代表性的对齐标准是“3 H 对齐标准”,即 Helpfulness(有用性)、Honesty(诚实性)和 Harmlessness(无害性)。
实际上,世界上最会使用工具的智能体就是人类,人类不断发明新的技术与工具,拓展自己的认知与能力边界。
GPT 模型简史
GPT 系列模型的基本原理是训练模型学习恢复预训练文本数据,将广泛的世界知识压缩到仅包含解码器(Decoder-Only)的 Transformer 模型中,从而使模型能够学习获得较为全面的能力。其中,两个关键要素是:(I)训练能够准确预测下一个词的 Transformer (只包含解码器)语言模型;(II)扩展语言模型的规模以及扩展预训练数据的规模。
当谷歌 2017 年推出基于注意力机制的 Transformer 模型后,OpenAI 团队迅速洞察到了其潜在的优越性,认为这种模型可能是一种大规模可扩展训练的理想架构。基于此,OpenAI 团队开始构建GPT 系列模型,并于 2018 年推出了第一代 GPT 模型—GPT-1,能够通过“通用文本训练-特定任务微调”的范式去解决下游任务。接下来,GPT-2 和 GPT-3 模型通过扩大预训练数据和模型参数规模,显著提升了模型性能,并且确立了基于自然语言形式的通用任务解决路径。在 GPT-3 的基础上,OpenAI 又通过代码训练、人类对齐、工具使用等技术对于模型性能不断升级,推出了功能强大的 GPT-3.5 系列模型。2022 年 11 月,ChatGPT 正式上线,能够以对话形式解决多种任务,使得用户能够通过网络 API 体验到语言模型的强大功能。2023 年 3 月,OpenAI 推出了标志性的 GPT-4 模型,将模型能力提升至全新高度,并将其扩展至拥有多模态功能的 GPT-4V 模型。
反观 GPT 系列模型的发展历程,有两点令人印象深刻。第一点是可拓展的训练架构与学习范式:Transformer 架构能够拓展到百亿、千亿甚至万亿参数规模,并且将预训练任务统一为预测下一个词这一通用学习范式;第二点是对于数据质量与数据规模的重视:不同于 BERT 时代的预训练语言模型,这次大语言模型的成功与数据有着更为紧密的关系,高质量数据、超大规模数据成为大语言模型的关键基础。
在 GPT-1 出现之前,构建高性能 NLP 神经网络的常用方法是利用监督学习。这种学习技术使用大量的手动标记数据。
GPT-1
- GPT-1 的作者提出了一种新的学习过程,其中引入了无监督的预训练步骤。这个预训练步骤不需要标记数据。相反,他们训练模型来预测下一个标记。
- 由于采用了可以并行化的 Transformer 架构,预训练步骤是在大量数据上进行的。
- GPT-1 是小模型,它无法在不经过微调的情况下执行复杂任务。因此,人们将微调作为第二个监督学习步骤,让模型在一小部分手动标记的数据上进行微调,从而适应特定的目标任务。比如,在情感分析等分类任务中,可能需要在一小部分手动标记的文本示例上重新训练模型,以使其达到不错的准确度。这个过程使模型在初始的预训练阶段习得的参数得到修改,从而更好地适应具体的任务。
- 尽管规模相对较小,但 GPT-1 在仅用少量手动标记的数据进行微调后,能够出色地完成多个 NLP 任务。GPT-1 的架构包括一个解码器(与原始 Transformer 架构中的解码器类似),具有 1.17 亿个参数。作为首个 GPT 模型,它为更强大的模型铺平了道路。后续的 GPT 模型使用更大的数据集和更多的参数,更好地利用了 Transformer 架构的潜力。
GPT-2
- 2019 年初,OpenAI 提出了 GPT-2。这是 GPT-1 的一个扩展版本,其参数量和训练数据集的规模大约是 GPT-1 的 10 倍。这个新版本的参数量为 15 亿,训练文本为 40 GB。2019 年 11 月,OpenAI 发布了完整版的 GPT-2 模型。
- GPT-2 是公开可用的,可以从 Hugging Face 或 GitHub 下载。
- GPT-2 表明,使用更大的数据集训练更大的语言模型可以提高语言模型的任务处理能力,并使其在许多任务中超越已有模型。它还表明,更大的语言模型能够更好地处理自然语言。
从 GPT-3 到 InstructGPT
- 2020 年 6 月,OpenAI 发布了 GPT-3。GPT-2 和 GPT-3 之间的主要区别在于模型的大小和用于训练的数据量。
- 2021 年,OpenAI 发布了 GPT-3 模型的新版本,并取名为 InstructGPT。与原始的 GPT-3 基础模型不同,InstructGPT 模型通过强化学习和人类反馈进行优化。
- 从 GPT-3 模型到 InstructGPT 模型的训练过程主要有两个阶段:监督微调(supervised fine-tuning,SFT)和通过人类反馈进行强化学习 (reinforcement learning from human feedback,RLHF)。每个阶段都会针对前一阶段的结果进行微调。也就是说,SFT 阶段接收 GPT-3 模型并返回一个新模型。RLHF 阶段接收该模型并返回 InstructGPT 版本。
- 与基础的 GPT-3 模型相比,InstructGPT 模型能够针对用户的提问生成更准确的内容。OpenAI 建议使用 InstructGPT 模型,而非原始版本。
GPT-3.5、Codex 和 ChatGPT
- ChatGPT 是由 LLM 驱动的应用程序,而不是真正的LLM。ChatGPT 背后的 LLM 是 GPT-3.5 Turbo。
GPT-4
- 与 OpenAI GPT 家族中的其他模型不同,GPT-4 是第一个能够同时接收文本和图像的多模态模型。这意味着 GPT-4 在生成输出句子时会考虑图像和文本的上下文。这样一来,用户就可以将图像添加到提示词中并对其提问。
使用插件和微调优化 GPT 模型
- OpenAI 提供的插件服务允许该模型与可能由第三方开发的应用程序连接。这些插件使模型能够与开发人员定义的应用程序接口(application program interface,API)进行交互。这个过程可以极大地增强 GPT 模型的能力,因为它们可以通过各种操作访问外部世界。
- 想象一下,将来每家公司都可能希望拥有自己的 LLM 插件。就像我们今天在智能手机应用商店中看到的那样,可能会有一系列的插件集合。通过插件可以添加的应用程序数量可能是巨大的。
- 在其网站上,OpenAI 表示可以通过插件让 ChatGPT 执行以下操作:
检索实时信息,如体育赛事比分、股票价格、最新资讯等;检索基于知识的信息,如公司文档、个人笔记等; 代表用户执行操作,如预订航班、订购食品等; 准确地执行数学运算。
GPT-4 和ChatGPT 的 API
- OpenAI Playground 是一个基于 Web 的平台。你可以使用它直接测试 OpenAI 提供的语言模型,而无须编写代码。在 OpenAI Playground 上,你可以编写提示词,选择模型,并轻松查看模型生成的输出。要测试 OpenAI 提供的各种 LLM 在特定任务上的表现,OpenAI Playground 是绝佳的途径。
开源LLM
LLaMA
由于对公众开放了模型权重且性能优秀,LLaMA 已经成为了最受欢迎的开源大语言模型之一,许多研究工作都是以其为基座模型进行微调或继续预训练,衍生出了众多变体模型
中文指令. 原始的 LLaMA 模型的训练语料主要以英语为主,在中文任务上的表现比较一般。为了使 LLaMA 模型能够有效地支持中文,研究人员通常会选择扩展原始词汇表,在中文数据上进行继续预训练,并用中文指令数据对其进行微调。经过中文数据的训练,这些扩展模型不仅能更好地处理中文任务,在跨语言处理任务中也展现出了强大的潜力。目前常见的中文大语言模型有 Chinese LLaMA、Panda、Open-Chinese-LLaMA、Chinese Alpaca、YuLan-Chat 等。
垂域指令. LLaMA 虽然展现出了强大的通用基座模型能力,但是在特定的垂直领域(例如医学、教育、法律、数学等)的表现仍然较为局限。为了增强 LLaMA模型的垂域能力,很多工作基于搜集到的垂域相关的指令数据,或者采用垂域知识库以及相关专业文献等借助强大的闭源模型 API(例如 GPT-3.5、GPT-4 等)构建多轮对话数据,并使用这些指令数据对 LLaMA 进行指令微调。常见的垂域 LLaMA模型有 BenTsao(医学)、LAWGPT(法律)、TaoLi(教育)、Goat(数学)、Comucopia (金融)等。
多模态指令. 由于 LLaMA 模型作为纯语言模型的强大能力,许多的多模态模型都将其(或将其衍生模型)作为基础语言模型,搭配视觉模态的编码器,使用多模态指令对齐视觉表征与文本。与其他语言模型相比,Vicuna 在多模态语言模型中受到了更多的关注,由此形成了一系列基于 Vicuna 的多模态模型,包括LLaVA 、MiniGPT4 、InstructBLIP 和 PandaGPT
目前性能最强大的模型仍然主要以闭源为主。这些闭源模型通过 API(应用程序接口)形式进行调用,无需在本地运行模型即可使用。在闭源大语言模型领域,OpenAI 无疑是最具代表性和影响力的公司
LLM训练过程
- 从机器学习的观点来说,神经网络是一种具有特定模型结构的函数形式,而大语言模型则是一种基于 Transformer 结构的神经网络模型。因此,可以将大语言模型看作一种拥有大规模参数的函数,它的构建过程就是使用训练数据对于模型参数的拟合过程。
- 尽管所采用的训练方法与传统的机器学习模型(如多元线性回归模型的训练)可能存在不同,但是本质上都是在做模型参数的优化。大语言模型的优化目标更加泛化,不仅仅是为了解决某一种或者某一类特定任务,而是希望能够作为通用任务的求解器
- 一般来说,这个训练过程可以分为大规模预训练和指令微调与人类对齐两个阶段,一般来说,预训练是指使用与下游任务无关的大规模数据进行模型参数的初始训练,可以认为是为模型参数找到一个较好的“初值点”。
- 目前来说,比较广泛使用的微调技术是“指令微调”(也叫做有监督微调,Supervised Fine-tuning, SFT),通过使用任务输入与输出的配对数据进行模型训练,可以使得语言模型较好地掌握通过问答形式进行任务求解的能力。这种模仿示例数据进行学习的过程本质属于机器学习中的模仿学习(Imitation Learning)。
- 如何将语言模型 进行人类对齐。具体来说,主要引入了基于人类反馈的强化学习对齐方法 RLHF(Reinforcement Learning from Human Feedback),在指令微调后使用强化学习加 强模型的对齐能力。在 RLHF 算法中,需要训练一个符合人类价值观的奖励模型(Reward Model)。为此,需要标注人员针对大语言模型所生成的多条输出进行偏 好排序,并使用偏好数据训练奖励模型,用于判断模型的输出质量。
预训练
- 常用的预训练数据集:目前常用于训练大语言模型的代表性数据集合。根据其内容类型进行分类,这些语料库可以划分为:网页、书籍、维基百科、代码以及混合型数据集。
- 数据准备:根据来源不同,预训练数据主要分为两种类型:通用文本数据和专用文本数据。
- 数据预处理
指令微调与人类对齐
- 为了增强模型的任务解决能力,大语言模型在预训练之后需要进行适应性微调,通常涉及两个主要步骤,即指令微调(有监督微调)和对齐微调。
指令微调(Instruction Tuning)
指令微调(Instruction Tuning)是指使用自然语言形式的数据对预训练后的大语言模型进行参数微调,这一术语由谷歌研究员在 2022 年的一篇 ICLR 论文中正式提出 [39]。在另外一些参考文献中,指令微调也被称为有监督微调(Supervised Fine-tuning)[28] 或多任务提示训练(Multitask Prompted Training)[40]。指令微调过程需要首先收集或构建指令化的实例,然后通过有监督的方式对大语言模型的参数进行微调。经过指令微调后,大语言模型能够展现出较强的指令遵循能力,可以通过零样本学习的方式解决多种下游任务。
指令微调是一种基于格式化的指令示例数据(即任务描述与期望输出相配对的数据)对大语言模型进行训练的过程。在大语言模型的背景下,这种利用配对文本进行训练的方法也被广泛地称为监督微调(Supervised Fine-Tuning, SFT)。
指令微调的作用:总体来说,指令的质量比数量更为重要。指令微调中应该优先使用人工标注的多样性指令数据。然而,如何大规模标注符合人类需求的指令数据目前仍然缺乏规范性的指导标准(比如什么类型的数据更容易激发大模型的能力)。在实践中,可以使用 ChatGPT、GPT-4 等闭源大语言模型来合成、重写、筛选现有指令,并通过数量来弥补质量和多样性上的不足。
指令微调旨在使用人工构建的指令数据对于大语言模型进一步训练,从而增强或解锁大语言模型的能力。与预训练相比,指令微调的成本显著降低,大模型所需的指令数据量仅为预训练阶段的约万分之一甚至更少。
指令微调旨在指导模型学会理解自然语言指令,并据此完成相应的任务。通过指令微调,大模型能够获得较好的指令遵循与任务求解能力,无需下游任务的训练样本或者示例就可以解决训练中未见过的任务。
领域专业化适配:通用的大语言模型能够在传统自然语言处理任务(如生成和推理)以及日常生活任务(如头脑风暴)上取得较好的效果,然而它们在特定领域中(如医学、法律和金融等)的表现与领域专用模型的效果仍有一定差距。在实际应用中,可以针对大语言模型进行面向特定领域的指令微调,从而使之能够适配下游的任务。
指令微调的训练策略:在训练方式上,指令微调与预训练较为相似,很多设置包括数据组织形式都可以预训练阶段所采用的技术
人类对齐
- 实现人类对齐的关键技术——基于人类反馈的强化学习(Reinforcement Learning from Human Feedback, RLHF),包括人类反馈的收集方法、奖励模型的训练过程、强化学习训练策略以及相关的 RLHF工作。
- 对齐标准:三个具有代表性的对齐标准展开讨论,分别是有用性(Helpfulness)、诚实性(Honesty)和无害性(Harmlessness)
- RLHF 算法系统主要包括三个关键组成部分:需要与人类价值观对齐的模型、基于人类反馈数据学习的奖励模型以及用于训练大语言模型的强化学习算法。
- RLHF 的关键步骤
- 监督微调. 为了让待对齐语言模型具有较好的指令遵循能力,通常需要收集高质量的指令数据进行监督微调。
- 奖励模型训练. 第二步是使用人类反馈数据训练奖励模型。
- 强化学习训练. 在这一步骤中,语言模型对齐被转化为一个强化学习问题。
解码与部署
解码
- 当完成训练后,我们就可以将大语言模型部署到真实场景中进行使用。大语 言模型是通过文本生成的方式进行工作的。在自回归架构中,模型针对输入内容逐个单词生成输出内容的文本。这个过程一般被称为 解码。
- 解码策略 大语言模型的生成方式本质上是一个概率采样过程,需要合适的解码策略来生成合适的输出内容。
- 批次管理优化 在传统的解码操作中,通常会等待一整个批次的所有实例都结束后再进行下 一个批次的计算。然而,一个批次内的不同实例往往生成长度各异,因此经常会出现等待某一条实例(输出长度最长的实例)生成的情况。批次管理优化旨在通过增加计算中的批次大小来提高计 算强度。一个代表性的方法是 vLLM(细节参考第 9.2.4 节)所提出的连续批处理(Continuous Batching)技术 [174]。该技术不同于传统确定顺序的定长批次处理方 式,而是将每个输入实例视为一个请求,每个请求的处理过程可以分解为全量解 码阶段和若干个单步增量解码阶段。在实现中,连续批处理技术会通过启发式算 法来选择部分请求进行全量解码操作,或者选择一些请求进行单步增量解码操作。 通过这样细粒度的拆分,连续批处理技术在一步操作中能够容纳更多的请求(相当于提高批次大小),从而提升了计算强度。
- 解码策略优化 除了直接解决系统级别的内存墙问题,许多研究工作提出了针对自回归解码策略的改进方法,从而提高解码效率。下面主要介绍四种解码优化算法,包括推测解码(Speculative Decoding)、非自回归解码(Non-autoregressive Decoding)、早退机制(Early Exiting)与级联解码(Cascade Inference)。
部署
- 低资源部署策略 由于大模型的参数量巨大,在解码阶段需要占用大量的显存资源,因而在实际应用中的部署代价非常高。在本章中,我们将介绍一种常用的模型压缩方法
- 量化基础知识: 模型量化(Model Quantization),来减少大模型的显存占用,从而使得能够在资源有限的环境下使用大模型。
- 通常来说,模型量化方法可以分为两大类,即量化感知训练(Quantization-AwareTraining, QAT)和训练后量化(Post-Training Quantization, PTQ)。
- 其他模型压缩方法:模型蒸馏和模型剪枝。与模型量化不同,模型蒸馏和模型剪枝则通过精简模型的结构,进而减少参数的数量。
- 模型蒸馏 模型蒸馏(Model Distillation)的目标是将复杂模型(称为教师模型)包含的知识迁移到简单模型(称为学生模型)中,从而实现复杂模型的压缩。
- 模型剪枝 模型剪枝(Model Pruning)的目标是,在尽可能不损失模型性能的情况下,努力消减模型的参数数量,最终有效降低模型的显存需求以及算力开销。
评测与应用
微调大语言模型的评测
- 基于人类的评测
- 基于模型的评测.考虑到人工评测的成本高昂且耗时较长,一些研究工作使 用强大的闭源大语言模型(如 ChatGPT 和 GPT-4)来替代人类评估员 [68, 315],对微调大模型的输出进行自动评分或比较。
- 基于基准的评测. 使用已有的评测基准对于大语言模型进行性能评估已经成 为一种标准性的实践方法。这些评测基准通常包含一系列精心设计的任务,每个任务都对应着充足的测试样本,以确保能够全面而准确地衡量大语言模型的核心能力,如复杂推理、知识利用等。这种评估方法的主要优势在于其高度的自动化和可复用性。自动化的评估过程可以大大减少人工干预的需要,从而提高评估的效率与一致性。
公开综合评测体系 随着大语言模型研究的深入,研究者们相继发布了若干用于全面评估大语言模型性能的综合评测体系,从不同角度、不同层次对大语言模型的能力进行了全面而细致的考察。在本章节中,我们将介绍几种广泛应用的综合评测体系,具体包括 MMLU、BIG-Bench、HELM 和 C-Eval。
更多的评测使用方法详见:https://github.com/RUCAIBox/LLMBox/blob/main/utilization/README.md。
大语言模型的另外一个局限之处是,在面对训练数据之外的知识信息时,模型通常无法表现出较好的效果。为了应对这个问题,一个直接的方法是定期使用新数据对大语言模型进行更新。然而,这种方法存在两个显著的问题:一是微调大语言模型的成本昂贵,二是增量训练大语言模型可能会导致灾难性遗忘的现象,即模型在学习新知识时可能会忘记旧知识.
大语言模型的参数化知识很难及时更新。用外部知识源增强大语言模型是解决这一问题的一种实用方法。
复杂推理 复杂推理(Complex Reasoning)是指通过运用支持性证据或逻辑来推导结论或作出决策的能力,这一过程涉及对信息的深入分析与综合处理 [361, 362]。根据推理过程中涉及的逻辑和证据类型,可以将现有的复杂推理任务划分为三个主要类别:知识推理、符号推理和数学推理。
Transformer architecture(Transformer 架构)
一种常用于自然语言处理任务的神经网络架构。它基于自注意力机制,无须顺序处理数据,其并行性和效率高于循环神经网络和长短期记忆模型。GPT 基于 Transformer 架构。
Transformer 架构彻底改变了 NLP 领域,这主要是因为它能够有效地解决之前的 NLP 模型(如 RNN)存在的一个关键问题:很难处理长文本序列并记住其上下文。换句话说,RNN 在处理长文本序列时容易忘记上下文(也就是臭名昭著的“灾难性遗忘问题”),Transformer 则具备高效处理和编码上下文的能力。
这场革命的核心支柱是注意力机制,这是一个简单而又强大的机制。模型不再将文本序列中的所有词视为同等重要,而是在任务的每个步骤中关注最相关的词。交叉注意力和自注意力是基于注意力机制的两个架构模块,它们经常出现在 LLM 中。Transformer 架构广泛使用了交叉注意力模块和自注意力模块。
与 RNN 不同,Transformer 架构具有易于并行化的优势。这意味着 Transformer 架构可以同时处理输入文本的多个部分,而无须顺序处理。这样做可以提高计算速度和训练速度,因为模型的不同部分可以并行工作,而无须等待前一步骤完成。基于 Transformer 架构的模型所具备的并行处理能力与图形处理单元(graphics processing unit,GPU)的架构完美契合,后者专用于同时处理多个计算任务。由于高度的并行性和强大的计算能力,GPU 非常适合用于训练和运行基于 Transformer 架构的模型。硬件上的这一进展使数据科学家能够在大型数据集上训练模型,从而为开发 LLM 铺平了道路。
attention mechanism(注意力机制):神经网络架构的一个组件,它使模型在生成输出时能够关注输入的不同部分。注意力机制是 Transformer 架构的关键,使其能够有效地处理长数据序列。
模型架构
- Transformer 模型 当前主流的大语言模型都基于 Transformer 模型进行设计的。Transformer 是由 多层的多头自注意力(Multi-head Self-attention)模块堆叠而成的神经网络模型。原始的 Transformer 模型由编码器和解码器两个部分构成,而这两个部分实际上可以独立使用,例如基于编码器架构的 BERT 模型 [13] 和解码器架构的 GPT 模型 [14]。
- 与 BERT 等早期的预训练语言模型相比,大语言模型的特点是使用了更长的向量维度、更深的层数,进而包含了更大规模的模型参数,并主要使用解码器架构,对于 Transformer 本身的结构与配置改变并不大。
prompt(提示词)
- 输入给语言模型的内容,模型通过它生成一个输出。比如,在 GPT 模型中,提示词可以是半句话或一个问题,模型将基于此补全文本。
- 提示词不仅适用于 OpenAI API,而且是所有 LLM 的入口点。简单地说,提示词就是用户发送给模型的输入文本,用于指导模型执行特定任务。
prompt engineering(提示工程)
设计和优化提示词,以从语言模型中获得所需的输出。这可能涉及指定响应的格式,在提示词中提供示例,或要求模型逐步思考。
提示工程是一门新兴的学科,专注于以最佳实践构建 LLM 的最佳输入,从而尽可能以程序化方式生成目标输出。AI 工程师必须知道如何与 AI 进行交互,以获取可用于应用程序的有利结果。此外,AI 工程师还必须知道如何正确提问和编写高质量的提示词。
通常需要在提示词中定义三大要素:角色、上下文和任务
逐步思考:在提示词末尾添加逐步思考的字样(比如示例中的“Let’s think step by step”)后,模型开始通过拆分问题来进行推理。它可能需要一些时间来进行推理,从而解决之前无法在一次尝试中解决的问题。
实现少样本学习(few-shot learning):LLM 仅通过提示词中的几个示例就能进行概括并给出有价值的结果。
单样本学习(one-shot learning)。顾名思 义,在单样本学习中,我们只提供一个示例来帮助模型执行任务。尽管这种方法提供的指导比少样本学习要少,但对于简单的任务或 LLM 已经具备丰富背景知识的主题,它可能很有效。单样本学习的优点是更简单、生成速度更快、计算成本更低(因而 API 使用成本更低)。然而,对于复杂的任务或需要更深入理解所需结果的情况,少样本学习的效果可能更好。
改善提示效果
- 指示模型提出更多问题
- 在提示词的末尾,询问模型是否理解问题并指示模型提出更多问题。如果你正在构建基于聊天机器人的解决方案,那么这样做非常有效。举例来说,你可以在提示词的末尾添加如下文本:
- 你清楚地理解我的请求了吗?如果没有,请问我关于上下文的问题。这样一来,当我回答时,你就能够更高效地执行我所请求的任务。
- 格式化输出
- 重复指示
- 经验表明,重复指示会取得良好的效果,尤其是当提示词很长时。基本思路是,在提示词中多次添加相同的指令,但每次采用不同的表述方式。
- 指示模型提出更多问题
使用负面提示:在文本生成场景中,负面提示是指通过指定不希望在输出中看到的内容来引导模型。负面提示作为约束或指南,用于滤除某些类型的回答。
添加长度限制:限制长度通常是不错的做法。如果你只希望模型回答 1 个词或者 10个句子,那么不妨将要求添加到提示词中。
chain of thought(CoT,思维链):一种提示工程技术,核心思想是通过向大语言模型展示少量的示例,在示例中将具体问题拆分成多个推理步骤,并要求模型遵循多步,比如“让我们逐步思考”。这会改善模型在执行复杂的推理任务(算术推理、常识推理和符号推理)时的表现。
你可以将这些技巧结合起来使用,以获得更好的效果。开发人员的工作是找到最有效的提示词来解决特定的问题。请记住,提示工程是一个反复试错的迭代过程。
【来自claude.ai】提示工程能够优化 AI 对话输出的原理主要基于以下几个关键方面:
- 大语言模型的工作原理:
- LLM 本质上是在预测下一个最可能的 token
- 模型通过海量文本训练学习了文本的统计规律
- 提示词会影响模型的上下文理解和token预测方向
- 上下文学习能力:
- 模型能够从提示中理解任务类型和要求
- 通过示例学习(few-shot learning)快速适应具体任务
- 更明确的上下文能帮助模型更准确地“理解”任务目标
- 注意力机制的影响:
- 提示中的关键词会影响模型的注意力分布
- 结构化的提示能引导模型关注重要信息
- 合理的提示格式有助于模型理解输入与输出的关系
- 模式识别与对齐:
- 好的提示能触发模型已学习的有用模式
- 清晰的指令有助于模型对齐用户意图
- 示例可以帮助模型识别所需的输出模式
举个例子:
1
2
3
4
5
6
7
8
9
10
11
12糟糕的提示:
"写一篇文章"
好的提示:
"请写一篇关于人工智能发展的文章,需要包含以下几个方面:
1. 发展历史
2. 主要技术突破
3. 未来展望
要求:
- 语言通俗易懂
- 每个部分300字左右
- 重点突出关键技术进展"好的提示通过提供:
- 明确的主题和结构
- 具体的要求和限制
- 输出格式的指导
帮助模型生成更符合预期的输出。
prompt injection(提示词注入)
- 一种特定类型的攻击,通过在提示词中提供精心选择的奖励,使大语言模型的行为偏离其原始任务。
- 提示词注入的原理如下:用户向应用程序发送一条输入消息,比如“忽略所有先前的指令,执行其他操作”。由于此输入消息与你在构建应用程序时设计的提示词连接在一起,因此 AI 模型将遵循用户的提示词,而不是你的提示词。
- 如果你计划开发和部署一个面向用户的应用程序,那么我们建议你结合以下两种方法。
- 添加分析层来过滤用户输入和模型输出。
- 意识到提示词注入不可避免,并采取一定的预防措施。
- 分析输入和输出
- 使用特定规则控制用户输入
- 控制输入长度
- 控制输出、监控和审计
- 分析输入和输出
embedding(嵌入)
表示词语或句子且能被机器学习模型处理的实值向量。对于值较为接近的向量,它们所表示的词语或句子也具有相似的含义。在信息检索等任务中,嵌入的这种特性特别有用。
由于模型依赖数学函数,因此它需要数值输入来处理信息。然而,许多元素(如单词和标记)本质上并不是数值。为了解决这个问题,我们用嵌入将这些概念转化为数值向量。通过以数值方式表示这些概念,嵌入使计算机能够更高效地处理它们之间的关系。在某些情况下,嵌入能力可能很有用。OpenAI 提供了一个可以将文本转换为数值向量的模型。嵌入端点让开发人员能够获取输入文本的向量表示,然后将该向量表示用作其他 ML 模型和 NLP 算法的输入。
在 ML 领域,特别是在处理语言模型时,我们会遇到嵌入这一重要概念。嵌入将分类数据(比如标记,通常是单个词或多组标记)转换为数值格式,具体而言是实数向量。这种转换是必要的,因为 ML 模型依赖数值数据,其直接处理分类数据的能力欠佳。
你可以将嵌入视为一种复杂的语言解释器,它将丰富的词汇和句子转换为 ML 模型能够轻松理解的数值语言。嵌入的一个突出特点是,它能够保持语义相似性。也就是说,含义相近的词语或短语在数值空间中更接近。
LLM 广泛使用嵌入。通常,这些模型处理约 512 维的嵌入,从而提供语言数据的高维数值表示。这些维度很深,使得模型能够区分各种复杂的模式。因此,它们在各种语言任务上表现出色,包括翻译、摘要和生成与人类对话相似的文本回应。
嵌入具有这样的属性:如果两段文本具有相似的含义,那么它们的向量表示也是相似的。
【来自claude.ai】RAG 和 embedding
- RAG 和 embedding 是紧密相关的技术,embedding 是实现 RAG 的关键技术之一。让我解释它们的关系和区别:
关系:
- Embedding 是 RAG 的基础技术
- RAG 在检索阶段需要使用 embedding 将文档和查询转换为向量
- 通过计算向量相似度来找到相关文档
- 在 RAG 流程中 embedding 的作用:
- 将知识库文档转换为向量存储
- 将用户查询转换为向量以便检索
- 通过向量相似度找到最相关的文档片段
区别:
- 功能定位不同:
- Embedding 是一种将文本转换为向量的基础技术
- RAG 是一个完整的应用框架,包含检索和生成两个主要步骤
- 使用场景不同:
- Embedding 可用于多种场景:文本相似度、聚类、分类等
- RAG 专注于增强 LLM 的知识和回答准确性
- 技术复杂度:
- Embedding 相对简单,主要关注向量转换和相似度计算
- RAG 更复杂,需要结合向量检索、上下文组织、LLM 生成等多个环节
- 输出结果:
- Embedding 输出是向量
- RAG 输出是生成的文本回答
简单来说,embedding 是 RAG 的重要组成部分,但 RAG 不仅仅是 embedding。RAG 使用 embedding 技术来实现其检索功能,然后将检索到的相关内容用于增强 LLM 的生成能力。
- RAG 和 embedding 是紧密相关的技术,embedding 是实现 RAG 的关键技术之一。让我解释它们的关系和区别:
RAG(检索增强生成)(Retrieval-Augmented Generation)
- 受限于训练数据的时效性和局限性,当涉及实时新闻或特定专业领域内知识时,大语言模型的生成结果可能不够准确。为弥补这一不足,研究人员引入了检索增强生成(Retrieval-Augmented Generation, RAG)技术。该技术旨在通过信息检索系统从外部知识库中获取相关信息,为大语言模型提供时效性强、领域相关的外部知识,以减少大语言模型生成内容中的错误。
fine-tuning(模型微调)
在微调过程中,预训练模型(如 GPT-3 或其他大语言模型)在一个较小、特定的数据集上进一步训练。微调旨在重复使用预训练模型的特征,并使其适应于特定任务。对于神经网络来说,这意味着保持结构不变,仅稍微改变模型的权重,而不是从头开始构建模型。
对比微调和少样本学习
- 微调是指针对特定任务在一组数据上重新训练现有模型,以提高模型的性能并使其回答更准确。在微调过程中,模型的内部参数得到更新。少样本学习则是通过提示词向模型提供有限数量的好例子,以指导模型根据这些例子给出目标结果。在少样本学习过程中,模型的内部参数不会被修改。
- 微调可以帮助我们得到高度专业化的模型,更准确地为特定任务提供与上下文相关的结果。
- 这使得微调非常适合有大量数据可用的场景。这种定制化确保模型生成的内容更符合目标领域的特定语言模式、词汇和语气 。
- 少样本学习是一种更灵活的方法,其数据使用率也更高,因为它不需要重新训练模型。当只有有限的示例可用或需要快速适应不同任务时,这种技巧非常有益。少样本学习让开发人员能够快速设计原型并尝试各种任务,这使其成为许多用例的实用选择。这两种方法的另一个关键选择标准是成本,毕竟使用和训练微调模型更贵。
迁移学习是指将从一个领域学到的知识应用于不同但相关的领域。正因为如此,你有时可能会听到人们在谈论微调时提到迁移学习。
微调除了文中提到的确保模型生成内容更符合目标领域的特定语言模式、词汇和语气,还有一个优势:你可以通过微调缩短每一次提示中重复的指令或提示词以节省成本或降低延迟,模型会记住通过微调获得的“内置”指令。因此,微调后,你可以在不牺牲提示质量的前提下,每次输入更短的提示词。
微调的应用
- 法律文本分析
- 自动代码审查
- 财务文档摘要
- 技术文档翻译
- 为专业领域生成内容
【来自claude.ai】指令微调(Instruction Tuning/RLHF)和Fine-tuning虽然都是大模型调优的方法,但它们是不同的技术:
- Fine-tuning:
- 更广义的概念,指在预训练模型基础上进行进一步训练
- 目的是让模型适应特定领域或任务
- 使用传统的监督学习方法
- 训练数据通常是输入-输出对
- 例如:用医疗数据fine-tune GPT模型使其更擅长医疗领域
- 指令微调:
- 是Fine-tuning的一种特殊形式
- 专注于提高模型遵循人类指令的能力
- 通常使用reinforcement learning from human feedback (RLHF)
- 训练数据包含明确的指令、期望的输出,以及人类反馈
- 例如:训练模型理解并执行“用简单的语言解释量子物理”这样的指令
- 关键区别:
- 指令微调更关注模型对指令的理解和执行能力
- Fine-tuning更关注领域适应性和特定任务性能
- 指令微调通常需要人类反馈作为训练信号
- Fine-tuning使用常规的监督学习方法
- Fine-tuning:
plugin(插件)
- 一种专门为语言模型设计的独立封装软件模块,用于扩展或增强模型的能力,可以帮助模型检索外部数据、执行计算任务、使用第三方服务等。
- 尽管包括 GPT-4 在内的 LLM 在各种任务上都表现出色,但它们仍然存在固有的局限性。比如,这些模型只能从训练数据中学习,这些数据往往过时或不适用于特定的应用。此外,它们的能力仅限于文本生成。我们还发现,LLM 不适用于某些任务,比如复杂的计算任务。
- 插件的目标是为 LLM 提供更广泛的功能,使 LLM 能够访问实时信息,进行复杂的数学运算,并利用第三方服务。 比如,插件可以使 LLM 检索体育比分和股票价格等实时信息,从企业文档等知识库中提取
Agents(智能体)
所谓智能体,就是一个可以处理用户输入、做出决策并选择适当工具来完成任务的组件。它以迭代方式工作,采取一系列行动,直到解决问题。
一种以大语言模型驱动的人工智能程序,能够自主感知环境并采取行动以实现目标,拥有自主推理决策、规划行动、检索记忆、选择工具执行任务等能力。
大语言模型智能体的构建过程,将围绕三个基本组件进行介绍,包括 记忆组件(Memory)、规划组件(Planning)2 和执行组件(Execution)。
大语言模型智能体的典型应用 大语言模型智能体在自主解决复杂任务方面展现出了巨大的潜力,不仅能够胜任特定任务,还可以构建面向复杂场景的虚拟仿真环境。本节将介绍三个大语言模型智能体的典型应用案例。 WebGPT WebGPT [31] 是由 OpenAI 开发的一款具有信息检索能力的大语言模型,它基于 GPT-3 模型微调得到,可以看作是大语言模型智能体的一个早期雏形。WebGPT部署在一个基于文本的网页浏览环境,用以增强大语言模型对于外部知识的获取能力。作为一个单智能体系统,WebGPT 具备自主搜索、自然语言交互以及信息整合分析等特点,能够理解用户的自然语言查询,自动在互联网上搜索相关网页。根据搜索结果,WebGPT 能够点击、浏览、收藏相关网页信息,对搜索结果进行分析和整合,最终以自然语言的形式提供准确全面的回答,并提供参考文献。WebGPT在基于人类评估的问答任务中,获得了与真实用户答案准确率相当的效果。 MetaGPT MetaGPT [308] 是一个基于多智能体系统的协作框架,旨在模仿人类组织的运作方式,模拟软件开发过程中的不同角色和协作。相关角色包括产品经理、架构师、项目经理、软件工程师及测试工程师等,并遵循标准化的软件工程运作流程对不同角色进行协调,覆盖了需求分析、需求文档撰写、系统设计、工作分配、
其他相关知识点
- AI hallucination(AI 幻觉):AI 生成的内容与现实世界的知识不一致或与实际数据显著不同的现象。在大多数情况下,模型的输出是与提问相关的,并且完全可用,但是在使用语言模型时需要小心,因为它们给出的回答可能不准确。这种回答通常被称为 AI 幻觉,即 AI 自信地给出一个回答,但是这个回答是错误的,或者涉及虚构的信息。
- catastrophic forgetting(灾难性遗忘):这是模型的一种倾向,具体指模型在学习新数据时忘记先前学到的信息。这种限制主要影响循环神经网络。循环神经网络在处理长文本序列时难以保持上下文。
- foundation model(基础模型):一类 AI 模型,包括但不限于大语言模型。基础模型是在大量未标记数据上进行训练的。这类模型可以执行各种任务,如图像分析和文本翻译。基础模型的关键特点是能够通过无监督学习从原始数据中学习,并能够通过微调来执行特定任务。
- Generative AI(GenAI,生成式人工智能):人工智能的一个子领域,专注于通过学习现有数据模式或示例来生成新的内容,包括文本、代码、图像、音频等,常见应用包括聊天机器人、创意图像生成和编辑、代码辅助编写等。
- Generative Pre-trained Transformer(GPT,生成式预训练Transformer):由 OpenAI 开发的一种大语言模型。GPT 基于 Transformer 架构,并在大量文本数据的基础上进行训练。这类模型能够通过迭代地预测序列中的下一个单词来生成连贯且与上下文相关的句子。
- inference(推理):使用训练过的机器学习模型进行预测和判断的过程。
information retrieval(信息检索):在一组资源中查找与给定查询相关的信息。信息检索能力体现了大语言模型从数据集中提取相关信息以回答问题的能力。 - language model(语言模型):用于自然语言处理的人工智能模型,能够阅读和生成人类语言。语言模型是对词序列的概率分布,通过训练文本数据来学习一门语言的模式和结构。
- large language model(LLM,大语言模型):具有大量参数(参数量通常为数十亿,甚至千亿以上)的语言模型,经过大规模文本语料库的训练。GPT-4 和 ChatGPT 就属于 LLM,它们能够生成自然语言文本、处理复杂语境并解答难题。
- long short-term memory(LSTM,长短期记忆):一种用于处理序列数据中的短期及长期依赖关系的循环神经网络架构。然而,基于 Transformer 的大语言模型(如 GPT 模型)不再使用LSTM,而使用注意力机制。
- multimodal model(多模态模型):能够处理和融合多种数据的模型。这些数据可以包括文本、图像、音频、视频等不同模态的数据。它为计算机提供更接近于人类感知的场景。
- n-gram:一种算法,常用于根据词频预测字符串中的下一个单词。这是一种在早期自然语言处理中常用的文本补全算法。后来,n-gram 被循环神经网络取代,再后来又被基于 Transformer 的算法取代。
- natural language processing(NLP,自然语言处理):人工智能的一个子领域,专注于计算机与人类之间的文本交互。它使计算机程序能够处理自然语言并做出有意义的回应。
- parameter(参数)
对大语言模型而言,参数是它的权重。在训练阶段,模型根据模型创建者选择的优化策略来优化这些系数。参数量是模型大小和复杂性的衡量标准。参数量经常用于比较大语言模型。一般而言,模型的参数越多,它的学习能力和处理复杂数据的能力就越强。 - pre-trained(预训练)
机器学习模型在大型和通用的数据集上进行的初始训练阶段。对于一个新给定的任务,预训练模型可以针对该任务进行微调。 - recurrent neural network(RNN,循环神经网络):一类表现出时间动态行为的神经网络,适用于涉及序列数据的任务,如文本或时间序列。
- reinforcement learning(RL,强化学习):一种机器学习方法,专注于在环境中训练模型以最大化奖励信号。模型接收反馈并利用该反馈来进一步学习和自我改进。
- reinforcement learning from human feedback(RLHF,通过人类反馈进行强化学习):一种将强化学习与人类反馈相结合的训练人工智能系统的先进技术,该技术涉及使用人类反馈来创建奖励信号,继而使用该信号通过强化学习来改进模型的行为。
- sequence-to-sequence model(Seq2Seq 模型,序列到序列模型):这类模型将一个领域的序列转换为另一个领域的序列。它通常用于机器翻译和文本摘要等任务。Seq2Seq 模型通常使用循环神经网络或 Transformer 来处理输入序列和输出序列。
- supervised fine-tuning(SFT,监督微调):采用预先训练好的神经网络模型,并针对特定任务或领域在少量的监督数据上对其进行重新训练。
- supervised learning(监督学习):一种机器学习方法,可以从训练资料中学到或建立一个模式,以达到准确分类或预测结果的目的。
- synthetic data(合成数据):人工创建的数据,而不是从真实事件中收集的数据。当真实数据不可用或不足时,我们通常在机器学习任务中使用合成数据。比如,像 GPT 这样的语言模型可以为各种应用场景生成文本类型的合成数据。
- temperature(温度):大语言模型的一个参数,用于控制模型输出的随机性。温度值越高,模型结果的随机性越强;温度值为 0 表示模型结果具有确定性(在 OpenAI 模型中,温度值为 0 表示模型结果近似确定)。
- text completion(文本补全):大语言模型根据初始的单词、句子或段落生成文本的能力。文本是根据下一个最有可能出现的单词生成的。
- token(标记):字母、字母对、单词或特殊字符。在自然语言处理中,文本被分解成标记。在大语言模型分析输入提示词之前,输入提示词被分解成标记,但输出文本也是逐个标记生成的。
- tokenization(标记化):将文本中的句子、段落切分成一个一个的标记,保证每个标记拥有相对完整和独立的语义,以供后续任务使用(比如作为嵌入或者模型的输入)。
- transfer learning(迁移学习):一种机器学习技术,其中在一个任务上训练的模型被重复利用于另一个相关任务。比如,GPT 在大量文本语料库上进行预训练,然后可以使用较少的数据进行微调,以适用于特定任务。
- unsupervised learning(无监督学习):一种机器学习方法,它使用机器学习算法来分析未标记的数据集并进行聚类。这些算法无须人工干预即可发现隐藏的模式或给数据分组。
- zero-shot learning(零样本学习):一个机器学习概念,即大语言模型对在训练期间没有明确见过的情况进行预测。任务直接呈现在提示词中,模型利用其预训练的知识生成回应。
LangChain
- LangChain 框架可能更适合大型项目
- LangChain 是专用于开发 LLM 驱动型应用程序的框架。
- LangChain 框架的关键模块
- Models(模型):该模块是由 LangChain 提供的标准接口,你可以通过它与各种 LLM进行交互。LangChain 支持集成 OpenAI、Hugging Face、Cohere、GPT4All 等提供商提供的不同类型的模型。
- Prompts(提示词):提示词已成为 LLM 编程的新标准。该模块包含许多用于管理提示词的工具。
- Indexes(索引):该模块让你能够将 LLM 与你的数据结合使用
- Chains(链):通过该模块,LangChain 提供了 Chain 接口。你可以使用该接口创建一个调用序列,将多个模型或提示词组合在一起。
- Agents(智能体):该模块引入了 Agent 接口。所谓智能体,就是一个可以处理用户输入、做出决策并选择适当工具来完成任务的组件。它以迭代方式工作,采取一系列行动,直到解决问题。
- Memory(记忆):该模块让你能够在链调用或智能体调用之间维持状态。默认情况下,链和智能体是无状态的。这意味着它们独立地处理每个传入的请求,就像LLM 一样。
Hugging Face
- Hugging Face 是一个致力于推动自然语言处理技术进步的开源社区,专注于为研究人员和工程师提供高效、易用且可重复的自然语言处理技术解决方案。这些解决方案既包括基础的技术流程,如预训练和微调,也涉及具体的应用任务,包括对话系统、翻译等。Hugging Face 平台上的代码大部分基于目前主流的深度学习框架实现完成的,如 PyTorch 和 TensorFlow。为了满足广泛的研究与应用需求,Hugging Face 发布了一系列代码库
个人理解(使用claude.ai 或 open.ai 优化过)
- 通过大量数据进行自监督预训练(Pre-training),之后使用监督学习(SFT)和强化学习(RLHF)等方法训练大语言模型。模型会在训练过程中表现出一些涌现能力,即随着规模增长获得的意外新能力。
- 训练之后的大模型可以这样比喻理解:对应一系列复杂的“处理规则”(相当于函数)以及训练时获得的“知识”(相当于多维度的数据)。这些规则决定如何处理输入信息,而知识则帮助模型理解和回应各种问题。就像一个经验丰富的专家,既有处理问题的方法,也有丰富的知识储备。
- 使用RAG是通过嵌入技术将外部知识转换为向量形式存储,当模型回答问题时,会同时使用:
- 模型自身通过训练获得的知识(存在参数/权重中)
- 通过检索获得的外部知识(存在向量数据库中)- (在运行时动态加载到模型的“上下文窗口”中;只是临时作为输入的一部分被模型处理)
- 嵌入技术在RAG中起到了关键作用:它能把文本转换成向量形式,使得模型能够理解和使用这些外部知识。
- 微调是通过调整模型的参数权重来优化其性能的过程。它并不等同于新建一个全新的模型,而是基于预训练模型,通过新的数据对部分或全部权重进行进一步优化,以适应特定任务或领域需求。需要注意的是,模型本身并不直接包含训练数据,而是通过参数权重间接“记住”了训练数据中的语言模式和知识。因此,微调的过程不会调整模型使用的原始数据,而是调整模型基于新数据学习到的知识表示和行为。
- 关于提示词技巧:提示词的设计就像与人交流时语言清晰、有条理,并能准确表达需求的人。这种沟通方式能够让模型更好地理解意图,从而产出符合预期的结果,因此提示词的技巧与良好的表达能力相辅相成,具有高度的共鸣。
- 在实际应用中,通常会有一个基础模型,它通过大量、多元化的训练数据应对大多数常见问题。这是一个通用的模型,具备广泛的能力。然而,针对特定领域或任务需求,可以对其进行微调或在特定领域的数据上进行训练,以构建不同的模型或智能体。与此同时,可能还会通过插件等方式增强模型的功能,以弥补基础模型在某些方面的不足。
具体过程通常是:通过用户输入,首先对语义进行分析,然后根据需求将任务转发给相应的智能体进行处理。整个系统由多个智能体组成,这些智能体可以互相协作,共同完成复杂的任务,从而形成一个多智能体系统。
这种架构通过将任务分配给不同的智能体,使得每个智能体可以专注于其擅长的领域,进而提高系统的整体效率和精准度。
个人扩展思考
- 关于替代人的问题:目前大模型还只是工具,不能完全替代所有人,但可以提升很多人的效率,从而也替代部分人。
- 大模型受限于原理,能力有限:大语言模型的输出基于训练语料和训练过程中学到的概率分布生成。这意味着其生成的内容是在统计意义上最可能的回复。然而,单一模型可能在语料的广度和功能的多样性方面存在局限性,这可能导致其能力受限。
- AI无法承担责任或替代人类对错误决策的责任。
其他扩展
关于标记(token)【来自豆包】
在OpenAI中,标记(token)是其对文本进行处理和计费的基本单位. 标记的含义 标记可以是单词、单词的一部分、数字、标点符号等。例如,单词“hello”是一个标记,“don’t”会被拆分成“don”和“‘t”两个标记,“123”是一个标记,逗号“,”也是一个标记. 标记的原理 • 文本分割:OpenAI通过特定的标记化算法,将输入的文本和生成的输出文本都分解成一个个标记。比如对于句子“I am taking my dog on a walk.”,会被分割成“I”“am”“taking”“my”“dog”“on”“a”“walk”等标记,其中“taking”还可能进一步被拆分成“take”和“ing”. • 数值转换:分割后的标记会被转换为数值,以便模型能够进行处理和计算。模型在训练和推理过程中,都是基于这些数值化的标记来进行各种运算和生成文本. • 计费依据:OpenAI根据输入和输出文本中标记的总数来计算费用。例如,若输入的问题是50个标记长,得到的回答是150个标记长,那么此次交互总共使用了200个标记,再依据所使用模型的每1000个标记的单价,就可以算出此次的费用. 在OpenAI中,当你输入时指定的标记数量限制,实际使用的标记数量不会超过你所设定的限制。 例如,你设定输入标记限制为500,模型在处理时会尽量依据此限制来生成文本,一般情况下不会超出该数量 。不过,如果输入内容本身就超过了设定的限制,模型通常会截断超出部分,仅处理限制范围内的标记,以保证符合你所设定的上限。 最终的费用计算也是基于实际使用的标记数量,只要在输入时设定了标记数量限制,就不会出现因模型生成内容导致标记数量超出限制而增加费用的情况。
大模型是否能发现训练数据存在逻辑矛盾【来自豆包】
大模型通常不具备直接发现训练数据中逻辑矛盾的能力,原因主要有以下几点: • 训练机制的局限性:大模型的训练基于对大量文本数据的统计分析和模式识别,通过预测下一个单词或字符来生成文本,重点在于学习语言的表面形式和常见搭配,而非深入理解数据背后的逻辑关系和语义内涵。 例如,对于“苹果是红色的”和“苹果是绿色的”这两个相互矛盾的数据,模型只会学习到这两种表述都是可能出现的语言形式,而不会判断其逻辑矛盾. • 缺乏真实世界的理解和推理能力:大模型没有对现实世界的直接感知和体验,无法像人类一样基于常识和逻辑规则进行推理。比如面对“太阳从西边升起”和“太阳从东边升起”这两个矛盾数据,模型无法依据自然规律来识别其中的逻辑错误. • 难以对数据进行批判性评估:大模型不会对训练数据的真实性、准确性和一致性进行主动质疑和验证,而是将所有数据同等对待地学习,导致矛盾数据被无差别吸收,进而可能在生成文本时输出与矛盾数据相关的不合理内容.
How to study LLMs with no machine learning background? 【From Gork 2】
Studying Large Language Models (LLMs) from a zero machine learning background involves a step-by-step approach to build your understanding. Here's a concise guide: ### **1. Basics of Machine Learning:** - **Start with Fundamentals:** - Learn basic concepts like supervised vs. unsupervised learning, regression, classification, and neural networks. - Resources: - *Coursera's Machine Learning by Andrew Ng* - *Khan Academy's AI Course* ### **2. Python and Programming:** - **Learn Python:** - Python is crucial for ML development. Focus on data structures, control flow, and libraries like NumPy, Pandas. - Resources: - *Python for Everybody* on Coursera - *Automate the Boring Stuff with Python* ### **3. Deep Learning Basics:** - **Understand Neural Networks:** - Grasp concepts of neurons, layers, activation functions, backpropagation. - Resources: - *Deep Learning Specialization by Andrew Ng on Coursera* ### **4. Focus on NLP (Natural Language Processing):** - **Basics of NLP:** - Learn about tokenization, word embeddings (like Word2Vec, GloVe), and sequence models. - Resources: - *Natural Language Processing with Deep Learning* by Stanford on YouTube ### **5. Introduction to LLMs:** - **Concepts of LLMs:** - Study transformer architecture, attention mechanisms, and how LLMs are trained (like BERT, GPT). - Resources: - *Illustrated Transformer* by Jay Alammar - *Hugging Face's NLP Course* ### **6. Practical Experience:** - **Implement Small Projects:** - Start with fine-tuning pre-trained models rather than training from scratch due to computational constraints. - Use platforms like Google Colab or Kaggle for free GPU resources to run models. ### **7. Community and Resources:** - **Engage with Communities:** - Join forums like Stack Overflow, Reddit (r/MachineLearning, r/LanguageTechnology), and Discord groups. - **Read Papers and Blogs:** - Follow research papers on arXiv, and blogs by companies like Hugging Face or Google AI. ### **8. Advanced Learning:** - **Once you have a foundation:** - Dive into specifics of model architectures, optimization techniques, and deployment strategies. ### **9. Keep Learning:** - **Stay Updated:** - The field of LLMs is rapidly evolving. Follow conferences like NeurIPS or ACL for the latest advancements. Starting from zero, this journey will take time and dedication. Patience and consistent practice are key. Remember, each step builds on the previous one, so don't rush through the foundational learning.
从零开始构建大模型(如LLM)【来自 open.ai】
从零构建大模型(如LLM)包括设计模型架构(如Transformer)、准备和清洗大量数据集、实现和预训练模型(使用PyTorch或TensorFlow)、优化和调试(采用分布式训练和混合精度)、以及微调和部署。 常用工具有Hugging Face Datasets(数据处理)、PyTorch/TensorFlow(模型实现)、DeepSpeed(分布式训练)、TensorBoard(监控)、以及NVIDIA CUDA(硬件加速)。 构建过程中需要强大的计算资源,如多GPU或TPU集群,云服务(如AWS或Google Cloud)可提供支持。
Max Tokens、Context Window 和 Context Length
- grok3 (2025-02-24)
- Max Tokens、Context Window 和 Context Length 主要关注输入的限制,但它们也可能间接影响到输出,具体来说,通常与模型的生成输出长度或质量有关系。
- Max Tokens (最大令牌数)
- Max Tokens 既包括输入的令牌数,也包括模型生成的输出的令牌数。举个例子,假设一个模型的 Max Tokens 是 4096:
- 如果输入文本占用了 1000 个令牌,那么剩余的 3096 个令牌就可以用来生成输出。
- 如果输入文本占用的令牌数较多,那么可用来生成的输出就会变少,反之亦然。
- 所以,Max Tokens 会直接限制模型的输出长度,因为它是输入和输出令牌数的总和。
- Context Window(上下文窗口)
- Context Window 通常更侧重于模型在生成过程中“能看到”的上下文范围。对于长文本,如果输入超过了 Context Window 的限制,超出的部分会被截断,模型只会处理窗口内的文本内容,而不会利用超出部分来生成更合适的回答。
- 因此,Context Window 主要限制了模型在生成时能够参考的输入量,进而间接影响输出的质量、相关性和连贯性。
- Context Length(上下文长度)
- Context Length 指的是你实际输入给模型的文本长度,包括用户输入和可能的上下文(例如先前的对话历史)。它影响了模型的理解过程,并且通常是 Max Tokens 限制的一部分。
- 如果输入的 Context Length 较长(即文本较多),那么会减少模型在生成输出时可用的令牌数,进而影响输出的长度。
- 总结:
- Max Tokens 直接限制了输入和输出的总令牌数,影响输出的最大长度。
- Context Window 影响模型生成输出时能参考多少输入内容,因此间接影响输出的质量、相关性和连贯性。
- Context Length 是指输入的实际长度,它在占用较多令牌时可能会减少输出可用的令牌数,从而影响输出的长度。
- 所以,虽然这三个参数主要是控制输入的,但由于它们与模型的令牌处理能力密切相关,它们也会间接影响生成的输出。
构建大模型的过程
- From ChatGPT (4o) (2025-03-03)
- https://chatgpt.com/share/67c531cc-e618-800b-a49d-cae86ebde079
- 从头构建一个大模型(比如类似 GPT、LLaMA 这样的 Transformer 结构),涉及确定神经元个数(即隐藏层维度)、神经网络层数(深度)、以及激活函数的选择。这个过程通常需要结合理论分析和实验调优。
- 神经元个数决定了模型的表达能力,主要涉及两个关键参数:
- d_model(隐藏层维度):决定每个 token 的表示能力。
- d_ff(前馈层维度):影响非线性变换的能力
- 层数(L)决定了模型可以学习的层级信息。
- 激活函数的作用是引入非线性,否则整个网络只是线性变换,无法学习复杂模式。
训练后大型语言模型的组成
From Gork3 (2025-02-25)
关键要点
- 研究表明,大型语言模型训练完成后,其数据内容主要是参数,包括词向量和映射关系。
- 证据倾向于认为,这些参数是神经网络的权重和偏差,编码了从训练数据中学到的语言模式。
- 模型本身不存储原始训练数据,而是通过参数捕获语言的统计关系。
参数:这些是神经网络的权重和偏差,存储在模型文件中,用于处理输入并生成输出。
词向量(也称为嵌入),它们是单词的数值表示,捕捉单词的语义和句法意义。
映射关系,通过神经网络各层的权重定义,决定了如何处理这些词向量以生成文本。
结论:训练后的大型语言模型的数据内容是其参数,包括词向量和映射关系。这些参数通过嵌入层、前馈网络和注意力机制等组件实现,捕捉了语言的统计模式。虽然模型不直接存储训练数据,但其参数可能隐含记忆某些内容。
From ChatGPT(o4) (2025-03-03)
除上述的数据之外,还包括
- 模型架构(Neural Network 结构):指的是模型的层数、注意力机制、激活函数等,比如 config.json 里会定义 Transformer 结构、隐藏层大小、head 数量、dropout 率等
- 其他辅助信息:训练时的一些超参数、优化器状态等
这些数据以一定的格式和文件保存在大模型的训练结果中。
- 比如Hugging Face transformers 生态 里的 “事实标准”,但并不是所有大模型都会按这个格式存储。不同的框架、实现方式和研究机构可能会有自己的格式和规范。
- 不同模型格式要用 相应的加载器,不能混用。不同的深度学习框架、训练方式,甚至不同的硬件优化方式,都会影响模型的存储格式和加载方式。
如何加载大模型
神经网络中,权重和偏置用公式的表现形式
From ChatGPT(o4) (2025-03-03)
https://chatgpt.com/share/67c5365d-3fac-800b-87d4-df29d53da575
神经网络中的权重和偏置在前向传播时,基本上都是一次方程(线性变换),但整个神经网络通常是非线性映射,因为每层的输出会经过非线性激活函数。
在神经网络中,输入 X 的个数(也就是特征的维度)由具体的任务和数据决定
- 由数据决定(特征数量)
- 由网络结构决定
- 由数据预处理决定
发布的大模型,所指的参数个数怎么计算出来的
- From ChatGPT(o4) (2025-03-03)
- https://chatgpt.com/share/67c5365d-3fac-800b-87d4-df29d53da575
- 参数(parameters) 指的是整个模型的权重和偏置,包括所有层的权重矩阵和偏置向量
- 参数个数:由模型层数、神经元数量、词向量维度决定,影响模型的存储和计算复杂度。
用英语和中文询问大型语言模型有何不同
- From Gork3 (2025-03-03)
- 研究表明,使用英语或中文询问大型语言模型(LLM)的主要区别在于语言处理方式和模型性能可能因语言而异。
- 证据倾向于认为,英语因其丰富的训练数据,通常在某些任务上表现优于中文,但这取决于具体模型和任务。
- 令人意外的是,中文的字符处理方式(如基于字符的标记化)与英语的单词或子词标记化不同,这可能会影响模型的理解和生成能力。
Reference
- 《大模型应用开发极简入门:基于 GPT-4 和 ChatGPT》
- 《大语言模型》- LLMBook - https://github.com/RUCAIBox/LLMSurvey
- 《大规模语言模型:从理论到实践》- LLM-TAP