- 本文内容基本来源:网上资料总结
共识(Consensus) 和 一致性(Consistency)
- 分布式一致性(共识)协议 (consensus protocol)
- Consensus != Consistency
- CAP 定理中的 C 和数据库 ACID 的 C 才是真正的“一致性”—— consistency 问题
- 在早些的文献中,共识(consensus)也叫做协商(agreement)
- 共识(Consensus),很多时候会见到与一致性(Consistency)术语放在一起讨论。严谨地讲,两者的含义并不完全相同。
- 一致性的含义比共识宽泛,在不同场景(基于事务的数据库、分布式系统等)下意义不同。具体到分布式系统场景下,一致性指的是多个副本对外呈现的状态。如前面提到的顺序一致性、线性一致性,描述了多节点对数据状态的共同维护能力。而共识,则特指在分布式系统中多个节点之间对某个事情(例如多个事务请求,先执行谁?)达成一致意见的过程。因此,达成某种共识并不意味着就保障了一致性。
- 实践中,要保证系统满足不同程度的一致性,往往需要通过共识算法来达成。
- 分布式之系统底层原理
共识问题
- 在分布式系统中,共识就是系统中的多个节点对某个值达成一致。共识问题可以用数学语言来描述:一个分布式系统包含 n 个进程 {0, 1, 2,…, n-1},每个进程都有一个初值,进程之间互相通信,设计一种算法使得尽管出现故障,进程们仍协商出某个不可撤销的最终决定值,且每次执行都满足以下三个性质:
- 终止性(Termination):所有正确的进程最终都会认同某一个值。
- 协定性(Agreement):所有正确的进程认同的值都是同一个值。
- 完整性(Integrity),也称作有效性(Validity):如果正确的进程都提议同一个值,那么所有处于认同状态的正确进程都选择该值。
- 完整性可以有一些变化,例如,一种较弱的完整性是认定值等于某些正确经常提议的值,而不必是所有进程提议的值。完整性也隐含了,最终被认同的值必定是某个节点提出过的。
- 算法共识/一致性算法有两个最核心的约束:1) 安全性(Safety),2) 存活性(Liveness):
- Safety:保证决议(Value)结果是对的,无歧义的,不会出现错误情况。
- 只有是被提案者提出的提案才可能被最终批准;
- 在一次执行中,只批准(chosen)一个最终决议。被多数接受(accept)的结果成为决议;
- Liveness:保证决议过程能在有限时间内完成。
- 决议总会产生,并且学习者最终能获得被批准的决议。
- Safety:保证决议(Value)结果是对的,无歧义的,不会出现错误情况。
- 根据解决的场景是否允许拜占庭(Byzantine)错误,共识算法可以分为 Crash Fault Tolerance (CFT) 和 Byzantine Fault Tolerance(BFT)两类。
- 对于非拜占庭错误的情况,已经存在不少经典的算法,包括 Paxos(1990 年)、Raft(2014 年)及其变种等。这类容错算法往往性能比较好,处理较快,容忍不超过一半的故障节点。
- 对于要能容忍拜占庭错误的情况,包括 PBFT(Practical Byzantine Fault Tolerance,1999 年)为代表的确定性系列算法、PoW(1997 年)为代表的概率算法等。确定性算法一旦达成共识就不可逆转,即共识是最终结果;而概率类算法的共识结果则是临时的,随着时间推移或某种强化,共识结果被推翻的概率越来越小,最终成为事实上结果。拜占庭类容错算法往往性能较差,容忍不超过 1/3 的故障节点。
- 副本控制协议可以分为两大类:“中心化(centralized)副本控制协议”和“去中心化(decentralized)副本控制协议”。
分布式系统的几个主要难题
- 网络问题
- 时钟问题
- 节点故障问题
达成共识还可以解决分布式系统中的以下经典问题
- 互斥(Mutual exclusion):哪个进程进入临界区访问资源?
- 选主(Leader election):在单主复制的数据库,需要所有节点就哪个节点是领导者达成共识。如果一些由于网络故障而无法与其他节点通信,可能会产生两个领导者,它们都会接受写入,数据就可能会产生分歧,从而导致数据不一致或丢失。
- 原子提交(Atomic commit):跨多节点或跨多分区事务的数据库中,一个事务可能在某些节点上失败,但在其他节点上成功。如果我们想要维护这种事务的原子性,必须让所有节点对事务的结果达成共识:要么全部提交,要么全部中止/回滚。
- 总而言之,在共识的帮助下,分布式系统就可以像单一节点一样工作——所以共识问题是分布式系统最基本的问题。
FLP 不可能(FLP Impossibility)
- 早在 1985 年,Fischer、Lynch 和 Paterson (FLP)在 “Impossibility of Distributed Consensus with One Faulty Process[5]” 证明了:在一个异步系统中,即使只有一个进程出现了故障,也没有算法能保证达成共识。
- 简单来说,因为在一个异步系统中,进程可以随时发出响应,所以没有办法分辨一个进程是速度很慢还是已经崩溃,这不满足终止性(Termination)。
- FLP给后来的人们提供了研究的思路——不再尝试寻找异步通信系统中共识问题完全正确的解法。FLP 不可能是指无法确保达成共识,并不是说如果有一个进程出错,就永远无法达成共识。
同步系统中的共识
- Dolev 和 Strong 在论文 “Authenticated Algorithms for Byzantine Agreement[9]” 中证明了:同步系统中,如果 N 个进程中最多有 f 个会出现崩溃故障,那么经过 f + 1 轮消息传递后即可达成共识。
- 在一个有 f 个拜占庭故障节点的系统中,必须总共至少有 3f + 1 个节点才能够达成共识。即 N >= 3f + 1。
- 虽然同步系统下拜占庭将军问题的确存在解,但是代价很高,需要 O(N^f+1 ) 的信息交换量,只有在那些安全威胁很严重的地方使用(例如:航天工业)
- PBFT(Practical Byzantine Fault Tolerance)[12] 算法顾名思义是一种实用的拜占庭容错算法,由 Miguel Castro 和 Barbara Liskov 发表于 1999 年。
- 算法的主要细节不再展开。PBFT 也是通过使用同步假设保证活性来绕过 FLP 不可能。PBFT 算法容错数量同样也是 N >= 3f + 1,但只需要 O(n^2 ) 信息交换量,即每台计算机都需要与网络中其他所有计算机通讯。
一致性模型
- 一致性(Consistency)是指多副本(Replications)问题中的数据一致性。
- 强一致性:数据更新成功后,任意时刻所有副本中的数据都是一致的,一般采用同步的方式实现。
- 弱一致性:数据更新成功后,系统不承诺立即可以读到最新写入的值,也不承诺具体多久之后可以读到。
- 最终一致性:弱一致性的一种形式,数据更新成功后,系统不承诺立即可以返回最新写入的值,但是保证最终会返回上一次更新操作的值。
- 分布式中一致性是非常重要的,分为弱一致性和强一致性。现在主流的一致性协议一般都选择的是弱一致性的特殊版本:最终一致性。
CAP
- CAP是指在一个分布式系统中,一致性(Consistency)、可用性(Availability)、分区容错性(Partition tolerance)这三个要素最多只能同时实现两点,不可能三者兼顾。
- CAP理论提出就是针对分布式环境的,所以,P 这个属性是必须具备的。
- Consistency 一致性
一致性指“all nodes see the same data at the same time”,即更新操作成功并返回客户端完成后,所有节点在同一时间的数据完全一致。等同于所有节点拥有数据的最新版本。
CAP中的C指的是强一致性。 - Availability 可用性
可用性指“Reads and writes always succeed”,即服务一直可用,而且是正常响应时间。
对于一个可用性的分布式系统,每一个非故障的节点必须对每一个请求作出响应。如果不考虑一致性,这个是很好实现的,立即返回本地节点的数据即可,而不需要等到数据一致才返回。 - Partition Tolerance 分区容忍性
Tolerance也可以翻译为容错,分区容忍性具体指“the system continues to operate despite arbitrary message loss or failure of part of the system”,即系统容忍网络出现分区,分区之间网络不可达的情况,分区容忍性和扩展性紧密相关,Partition Tolerance特指在遇到某节点或网络分区故障的时候,仍然能够对外提供满足一致性和可用性的服务。
传统数据库都是假设不保证P的,因为传统数据库都是单机或者很小的本地集群,假设网络不存在问题,出现问题手工修复。所以,损失分区容错(P)只保证CA相当于就是一个单体应用,根本不是分布式。
分布式是要求单个节点故障(概率太高了)系统仍能完成运行。搭建分布式就是间接要求必须保证P,即P是现实,那C和A就无法同时做到,需要在这两者之间做平衡。
像银行系统,是通过损失可用性(A)来保障CP,银行系统是内网,很少出现分区不可达故障状态,一旦出现,不可达的节点对应的ATM就没法使用,即变为不可用。同时如果数据在各分区未达到一致,ATM也是Loading状态即不可用。
在互联网实践中,可用性又是极其重要的,因此大部分是通过损失一致性(C)来保障AP,当然也非完全牺牲一致性,使用弱一致性,即一定时间后一致的弱一致性,当数据还在同步时(WRITE之后),使用上一次的数据。
Google 2009年 在Transaction Across DataCenter 的分享中,对一致性协议在业内的实践做了一简单的总结,如下图所示,这是 CAP 理论在工业界应用的实践经验。
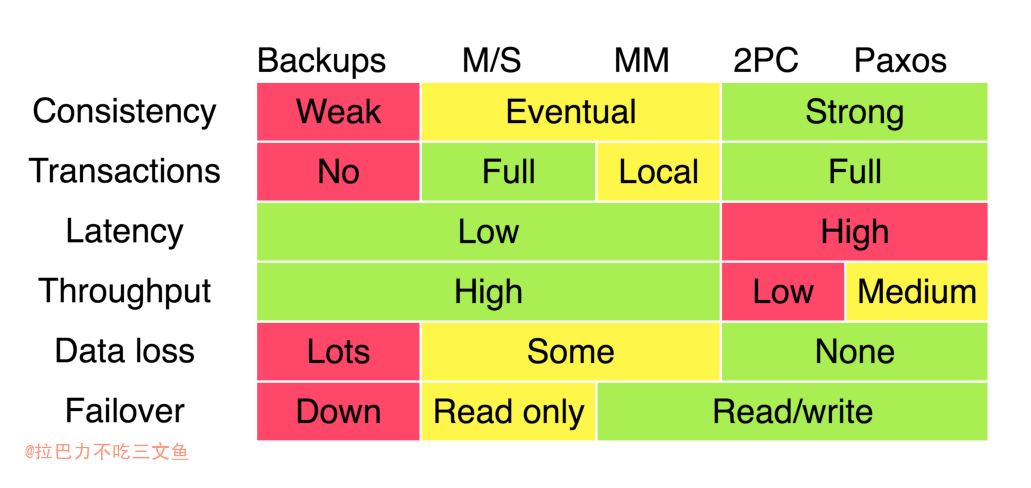
BASE 理论
- Basically Available(基本可用)
- Soft state(软状态)
- Eventually consistent(最终一致性)
- BASE 理论是对 CAP 中的一致性和可用性进行一个权衡的结果,理论的核心思想就是:我们无法做到强一致,但每个应用都可以根据自身的业务特点,采用适当的方式来使系统达到最终一致性。
- BASE理论是对大规模的互联网分布式系统实践的总结,用弱一致性来换取可用性,不同于ACID,属于AP系统。
ACID
- ACID(Atomicity原子性,Consistency一致性,Isolation隔离性,Durability持久性)是事务的特点,具有强一致性,一般用于单机事务,分布式事务若采用这个原则会丧失一定的可用性,属于CP系统。
分类
按单主和多主进行分类
- 单主协议,即整个分布式集群中只存在一个主节点。主备复制、2PC、 Paxos、Raft、ZAB。
- (不允许数据分歧):整个分布式系统就像一个单体系统,所有写操作都由主节点处理并且同步给其他副本。
- 多主协议,即整个集群中不只存在一个主节点。Pow、Gossip协议。
- (允许数据分歧):所有写操作可以由不同节点发起,并且同步给其他副本。
- 单主协议由一个主节点发出数据,传输给其余从节点,能保证数据传输的有序性。而多主协议则是从多个主节点出发传输数据,传输顺序具有随机性,因而数据的有序性无法得到保证,只保证最终数据的一致性。这是单主协议和多主协议之间最大的区别。
---单主--主备复制、2PC、 Paxos、Raft、ZAB | ---多主--Pow、Gossip
按CAP中的P分类
- 分区容忍的一致性协议跟所有的单主协议一样,它也是只有一个主节点负责写入(提供顺序一致性),但它跟 2PC 的区别在于它只需要保证大多数节点(一般是超过半数)达成一致就可以返回客户端结果,这样可以提高了性能,同时也能容忍网络分区(少数节点分区不会导致整个系统无法运行)。分区容忍的一致性算法保证大多数节点数据一致后才返回客户端,同样实现了顺序一致性。
---非P--主备复制、2PC | ---P --Paxos、Raft
算法简介
1、主备复制
- 主备复制可以说是最常用的数据复制方法,也是最基础的方法,很多其他协议都是基于它的变种。 主备复制要求所有的写操作都在主节点上进行,然后将操作的日志发送给其他副本。可以发现由于主备复制是有延迟的,所以它实现的是最终一致性。
- 主备复制的实现方式:主节点处理完写操作之后立即返回结果给客户端,写操作的日志异步同步给其他副本。这样的好处是性能高,客户端不需要等待数据同步,缺点是如果主节点同步数据给副本之前数据缺失了,那么这些数据就永久丢失了。MySQL 的主备同步就是典型的异步复制。
2、2PC
- 2PC 是典型的 CA 系统,为了保证一致性和可用性,2PC 一旦出现网络分区或者节点不可用就会被拒绝写操作,把系统变成只读的。
- 由于 2PC 容易出现节点宕机导致一直阻塞的情况,所以在数据复制的场景中不常用,一般多用于分布式事务中。
- 如果网络环境较好,该协议一般还是能很好的工作的,2PC广泛应用于关系数据库的分布式事务处理,如mysql的内部与外部XA都是基于2PC的,一般想要把多个操作打包未原子操作也可以用2PC。
|---1. Prepare(Vote Request) | |---2. Global Commit (1- return (Vote Commit)) (正常流程) | |---2. Global Rollback (1- return (Vote Abort)) (异常流程)
- 缺点:
- 性能问题(两个阶段都涉及同步等待阻塞,极大降低了吞吐量)
- 协调者单点故障问题
- 丢失消息导致的数据不一致问题
3、3PC
相对于2PC,3PC主要解决的单点故障问题,并减少阻塞。在2PC的基础上增加了CanCommit阶段,并引入了超时机制。一旦事务参与者迟迟没有收到协调者的Commit请求,就会自动进行本地commit,这样相对有效地解决了协调者单点故障的问题;但是性能问题和不一致问题仍然没有根本解决。
CanCommit阶段: 检查下自身状态的健康性,看有没有能力进行事务操作。
和2PC区别:
- 相比较2PC而言,3PC对于协调者(Coordinator)和参与者(Partcipant)都设置了超时时间,而2PC只有协调者才拥有超时机制。这个优化点,主要是避免了参与者在长时间无法与协调者节点通讯(协调者挂掉了)的情况下,无法释放资源的问题,因为参与者自身拥有超时机制会在超时后,自动进行本地commit从而进行释放资源。而这种机制也侧面降低了整个事务的阻塞时间和范围。
- 通过CanCommit、PreCommit、DoCommit三个阶段的设计,相较于2PC而言,多设置了一个缓冲阶段保证了在最后提交阶段之前各参与节点的状态是一致的。
无论是2PC还是3PC都无法彻底解决分布式的一致性问题。Google Chubby的作者Mike Burrows说过,“there is only one consensus protocol, and that’s Paxos”——all other approaches are just broken versions of Paxos。意即世上只有一种一致性算法,那就是Paxos,所有其他一致性算法都是Paxos算法的不完整版。
4、MVCC
- MVCC(Multi-version Cocurrent Control,多版本并发控制)技术。MVCC 技术最初也是在数据库系统中被提出,但这种思想并不局限于单机的分布式系统,在分布式系统中同样有效。
5、Paxos协议
- 2PC、3PC 两个协议的协调者都需要人为设置而无法自动生成,是不完整的分布式协议,而Paxos 就是一个真正的完整的分布式算法。系统一共有几个角色:Proposer(提出提案)、Acceptor(参与决策)、Learner(不参与提案,只负责接收已确定的提案,一般用于提高集群对外提供读服务的能力),实践中一个节点可以同时充当多个角色。
- 作者在描述Paxos时,列举了希腊城邦选举的例子,所以该算法又被称为希腊城邦算法。
- Paxos是非常经典的一致性协议,但是因为过于理论化,难以直接工程化,因此工业界出现了诸多基于Paxos思想出发的变种。虽然这些变种最终很多都和原始的Paxos有比较大的差距,甚至完全演变成了新的协议,但是作为奠基者的Paxos在分布式一致性协议中依然持有不可撼动的地位。
- Paxos协议的容错性很好,只要有超过半数的节点可用,整个集群就可以自己进行Leader选举,也可以对外服务,通常用来保证一份数据的多个副本之间的一致性,适用于构建一个分布式的一致性状态机。
- Google的分布式锁服务Chubby就是用了Paxos协议,而开源的ZooKeeper使用的是Paxos的变种ZAB协议。
6、Raft协议
- Raft协议是斯坦福的Diego Ongaro、John Ousterhout两人于2013年提出,作者表示流行的Paxos算法难以理解,且其过于理论化致使直接应用于工程实现时出现很多困难,因此作者希望提出一个能被大众比较容易地理解接受,且易于工程实现的协议。Raft由此应运而生。不得不说,Raft作为一种易于理解,且工程上能够快速实现一个较完整的原型的算法,受到业界的广泛追捧。
- Raft协议对标Paxos,容错性和性能都是一致的,但是Raft比Paxos更易理解和实施。系统分为几种角色:Leader(发出提案)、Follower(参与决策)、Candidate(Leader选举中的临时角色)。
- 在Raft协议出来之前,Paxos是分布式领域的事实标准,但是Raft的出现打破了这一个现状(raft作者也是这么想的,请看论文),Raft协议把Leader选举、日志复制、安全性等功能分离并模块化,使其更易理解和工程实现,将来发展怎样我们拭目以待(挺看好)。
- Raft协议目前被用于 cockrouchDB,TiKV等项目中
- Raft 算法实际上是 Multi-Paxos 的一个变种,通过新增两个约束:
- 追加日志约束:Raft 中追加节点的日志必须是串行连续的,而 Multi-Paxos 中则可以并发追加日志(实际上 Multi-Paxos 的并发也只是针对日志追加,最后应用到内部 State Machine 的时候还是必须保证顺序)。
- 选主限制:Raft 中只有那些拥有最新、最全日志的节点才能当选 Leader 节点,而 Multi-Paxos 由于允许并发写日志,因此无法确定一个拥有最新、最全日志的节点,因此可以选择任意一个节点作为 Leader,但是选主之后必须要把 Leader 节点的日志补全。
- 基于这两个限制,Raft 算法的实现比 Multi-Paxos 更加简单易懂,不过由于 Multi-Paxos 的并发度更高,因此从理论上来说 Multi-Paxos 的性能会更好一些,但是到现在为止业界也没有一份权威的测试报告来支撑这一观点。
Paxos和Raft的对比
- Paxos算法和Raft算法有显而易见的相同点和不同点。二者的共同点在于,它们本质上都是单主的一致性算法,且都以不存在拜占庭将军问题作为前提条件。二者的不同点在于,Paxos算法相对于Raft,更加理论化,原理上理解比较抽象,仅仅提供了一套理论原型,这导致很多人在工业上实现Paxos时,不得已需要做很多针对性的优化和改进,但是改进完却发现算法整体和Paxos相去甚远,无法从原理上保证新算法的正确性,这一点是Paxos难以工程化的一个很大原因。相比之下Raft描述清晰,作者将算法原型的实现步骤完整地列在论文里,极大地方便了业界的工程师实现该算法,因而能够受到更广泛的应用。
- 从根本上来看,Raft的核心思想和Paxos是非常一致的,甚至可以说,Raft是基于Paxos的一种具体化实现和改进,它让一致性算法更容易为人所接受,更容易得到实现。由此亦可见,Paxos在一致性算法中的奠基地位是不可撼动的。
7、Gossip算法
- Gossip又被称为流行病算法,它与流行病毒在人群中传播的性质类似,由初始的几个节点向周围互相传播,到后期的大规模互相传播,最终达到一致性。
- Gossip协议与上述所有协议最大的区别就是它是去中心化的,上面所有的协议都有一个类似于Leader的角色来统筹安排事务的响应、提交与中断,但是Gossip协议中就没有Leader,每个节点都是平等的。
- Gossip协议被广泛应用于P2P网络,同时一些分布式的数据库,如Redis集群的消息同步使用的也是Gossip协议,另一个重大应用是被用于比特币的交易信息和区块信息的传播。
- 去中心化的Gossip看起来很美好:没有单点故障,看似无上限的对外服务能力……本来随着Cassandra火了一把,但是现在Cassandra也被抛弃了,去中心化的架构貌似难以真正应用起来。归根到底我觉得还是因为去中心化本身管理太复杂,节点之间沟通成本高,最终一致等待时间较长……往更高处看,一个企业(甚至整个社会)不也是需要中心化的领导(或者制度)来管理吗,如果没有领导(或者制度)管理,大家就是一盘散沙,难成大事啊。
- 事实上现代互联网架构只要把单点做得足够强大,再加上若干个强一致的热备,一般问题都不大。
- 应用:数据同步;缺点:节点之间沟通成本高,最终一致等待时间较长
8、Pow(Proof of work)
- Proof-of-work算法又被称为Pow算法。工作量证明算法。
- Pow最为人所熟知的应用是比特币。代表者是比特币(BTC),区块链1.0
- PoW(Proof of Work,工作量证明)的字面意思是谁干的活多,谁的话语权就大,在一定层面上类似于现实生活中“多劳多得”的概念。以比特币为例,比特币挖矿就是通过计算符合某一个比特币区块头的哈希散列值争夺记账权。这个过程需要通过大量的计算实现,简单理解就是挖矿者进行的计算量越大(工作量大),它尝试解答问题的次数也就变得越多,解出正确答案的概率自然越高,从而就有大概率获得记账权,即该矿工所挖出的区块被串接入主链。
- 基于PoW节点网络的安全性令人堪忧。大于51%算力的攻击。
- 51%算力攻击目前仅在“PoW”共识机制中存在,因为“PoW”共识机制依赖算力计算获胜,也就是谁算得快,谁的胜率就高。在使用了“PoW”共识机制的区块链网络中,我们称参与计算哈希的所有计算机资源为算力,那么全网络的算力就是100%,当超过51%的算力掌握在同一阵营中时,这个阵营的计算哈希胜出的概率将会大幅提高。为什么是51%?50.1%不行吗?当然也是可以的,之所以取51%是为了取一个最接近50%,且比50%大的整数百分比,这样当算力值达到51%后的效果将会比50.1%的计算效果更明显。举个例子,如果诚实节点的算力值是50.1%,那么坏节点的算力值就是49.9%。两者的差距不算太大,这样容易导致最终的区块竞争你来我往、长期不分上下。如果算力资源分散,不是高度集中的,那么整个区块链网络是可信的。然而,当算力资源集中于某一阵营的时候,算力的拥有者就能使用算力资源去逆转区块,导致区块链分叉严重,
9、PoS(Proof of Stake)
- 代表者是以太坊(ETH),以太坊正在从PoW过渡到PoS,区块链2.0
- PoS(Proof of Stake,股权证明)是由点点币(PPCoin)首先应用的。该算法没有挖矿过程,而是在创世区块内写明股权分配比例,之后通过转让、交易的方式,也就是我们说的IPO(Initial Public Offerings)公开募股方式,逐渐分散到用户钱包地址中去,并通过“利息”的方式新增货币,实现对节点地址的奖励。PoS的意思是股份制。也就是说,谁的股份多,谁的话语权就大,这和现实生活中股份制公司的股东差不多。但是,在区块链的应用中,我们不可能真实地给链中的节点分配股份,取而代之的是另外一些东西,例如代币,让这些东西来充当股份,再将这些东西分配给链中的各节点。
- PoS共识算法具有下面的优缺点:(1)优点•缩短了共识达成的时间,链中共识块的速度更快。•不再需要大量消耗能源挖矿,节能。•作弊得不偿失。如果一名持有多于50%以上股权的人(节点)作弊,相当于他坑了自己,因为他是拥有股权最多的人,作弊导致的结果往往是拥有股权越多的人损失越多。(2)缺点•攻击成本低,只要节点有物品数量,例如代币数量,就能发起脏数据的区块攻击。•初始的代币分配是通过IPO方式发行的,这就导致“少数人”(通常是开发者)获得了大量成本极低的加密货币,在利益面前,很难保证这些人不会大量抛售。•拥有代币数量大的节点获得记账权的概率会更大,使得网络共识受少数富裕账户支配,从而失去公正性。
- 区块链2.0仍存在性能上的缺陷,难以支持大规模的商业应用开发。与支付宝在“双十一”时26.5万笔交易/秒的性能相比,像以太坊这样的区块链系统只能做到几百笔交易/秒的水平。交易需由多个参与方确认,是影响区块链性能的主要原因。
10、DPoS
- 代表者是柚子(EOS),区块链3.0
11、
- PBFT拜占庭容错,联盟链中常用。
Gossip算法和Pow算法对比
- 同为去中心化算法,Gossip算法和Pow算法都能实现超大集群的一致性,但是它们的特性可谓有天壤之别。Gossip算法往往应用于超大集群快速达成一致性的目的。它的特性是如流感一般超强的传播速度,以及自身能够管理的数量可观的节点数。但是对于流传的消息没有特别的管控,无法辨别其中的虚假信息,并且只关注与最终的一致性,不关心消息的顺序性。而Pow算法则完全专注于尽可能地解决“拜占庭将军”问题,防止消息的篡改。它可以不计代价地去要求各个节点参与竞选,以付出巨大算力为代价保证平台的安全性。
应用
- 区块链:PoW、PoS、Gossip
总结
2PC和TCC什么关系
2PC在“分布式一致性协议”的范畴,属于CA层面的一个协议,一般作为和其他协议(PAXOS,Raft)进行对比的形式出现。
2PC在“分布式事务”的范畴,属于数据库层面,XA协议的基础。TCC算是一种特殊的2PC。TCC事务的处理流程与2PC两阶段提交类似,不过2PC通常都是在跨库的DB层面,而TCC本质上就是一个应用层面的2PC,需要通过业务逻辑来实现。
TCC是分布式事务的范畴,但其本质也是分布式一致性的一种协议,只是特指业务上的协议。而一般情况下我们所说的分布式一致性协议,一般是指底层系统实现上的,偏向基础服务上的。如果以后有人对TCC进行改造,描述出底层系统(非业务)的TCC,那么它也属于这篇文章所包含的其中一种分布式一致性协议。对于其他分布式事务的实现方案同理。
其他
- 从Paxos到Raft再到EPaxos:一文总结:分布式一致性技术是如何演进的?
- 众所周知,Paxos是出了名的晦涩难懂,不仅难以理解,更难以实现。而Raft则以可理解性和易于实现为目标,Raft的提出大大降低了使用分布式一致性的门槛,将分布式一致性变的大众化、平民化,因此当Raft提出之后,迅速得到青睐,极大地推动了分布式一致性的工程应用。
- EPaxos的提出比Raft还早,但却长期无人问津,很大一个原因就是EPaxos实在是难以理解。EPaxos基于Paxos,但却比Paxos更难以理解,大大地阻碍了EPaxos的工程应用。不过,是金子总会发光的,EPaxos因着它独特的优势,终于被人们发现,具有广阔的前景。
- EPaxos更适用于跨AZ跨地域场景,对可用性要求极高的场景,Leader容易形成瓶颈的场景。Multi-Paxos和Raft本身非常相似,适用场景也类似,适用于内网场景,一般的高可用场景,Leader不容易形成瓶颈的场景。
Reference
- 分布式一致性协议概述
- 分布式系统:一致性协议
- 分布式一致性协议
- 分布式事务:深入理解什么是2PC、3PC及TCC协议
- 详解分布式一致性机制
- 漫谈分布式共识问题!!
- 分布式之系统底层原理!!!!
- 深度介绍分布式系统原理与设计
- [区块链:以太坊DApp开发实战]
- [区块链:分布式商业与智数未来]